
 Canal Youtube
Canal YoutubeOlá, nesse post vou trazer uma dificuldade recente que tive envolvendo um space do XTTS e o ZeroGPU do Hugging Face.
O problema me rendeu vários conhecimentos novos sobre python, Hugging Face e Zero GPU! E espero que possa ajudar alguém que esteja passando por algo parecido!
Estrutura do Space
O Space envolvido é este: Xtts – a Hugging Face Space by rrg92
Este space contém uma versão do XTTS, que é um modelo para clonar voz! Uma pessoa que tentou usar o space comentou que o clone de voz não estava funcionando. Quando eu fui testar, de fato não estava, mas todo o resto estava.
Para que você entenda os principais componentes envolvido nesse problema, vou resumir a estrutura:
- É um space Gradio (versão 5.5.0)
- Há dois arquivos (módulos) python relevantes para este caso:
xttsandapp.- xtts é onde eu coloco todos os imports para invocar o modelo XTTS e as funções que integram diretamente com o modelo
appé onde fica os imports, funcões e event listeners do Gradio. A partir daqui, elas chama o código do módulo xtts.
Essa estrutura é uma pequena adaptação do projetoxtts-streaming-server. Eu coloquei a API e o modelo na mesma app para poder usar o space com ZeroGPU.
- De todas as funções que esse projeto tem, as mais relevantes para este problema são:
xtts.predict_speakerEsta é a função que clona a voz. Basicamente, ela recebe o binário do arquivo e calcula os embeddings da voz, usando as funções da biblioteca do XTTS. Ele invoca o modelo usando model.get_conditioning_latents, passando o arquivo. Ela retorna esses embeddings, que podem ser posteriormente enviados para xtts.predict_speech como fonte da voz.xtts.predict_speech
Esta é a função que transforma texto em voz. Dos parâmetros que ela aceita, os mais relevantes para a gente são: o texto a ser transformado e ospeaker. Essespeakersão embeddings que representam a voz. O XTTS vem com uma gama de vozes de estúdio padrão, e também podemos gerar novos embeddings usandoxtts.predict_speaker. De qualquer forma, de uma forma ou outra, esses são os principais parâmetros. A função retorna o binário do áudio gerado.app.clone_voice
Esta é a função disparada quando alguém tenta clonar a voz.Ela recebe como primeiro parâmetro, o áudio de referência informado pelo usuário na interface. E um caminho do arquivo. Então, abrimos o arquivo e invocamos a funçãoxtts.predict_speakerapp.tts
Esta é a função invocada quando o usuário clica no botão TTS, na interface do Gradio. A função faz uma série de operações, mas tudo se resume em: determinar o texto, os embeddings dospeakerescolhido na interface, e invocarxtts.predict_speech.
E para finalizar, como eu queria rodar o TTS usando ZeroGPU, eu usei o decorator @spaces.GPU na função xtts.predict_speech. Este é o procedimento oficial documentado pelo Hugging Face quando queremos usar GPU.
Agora que você conhece a estrutura do space, vamos explorar dois problemas que eu me deparei!
Problema 1: probability tensor contains either inf, nan or element < 0
O primeiro problema que notei no processo de clone foi o erro retornado ao tentar gerar o texto com uma voz clonada:
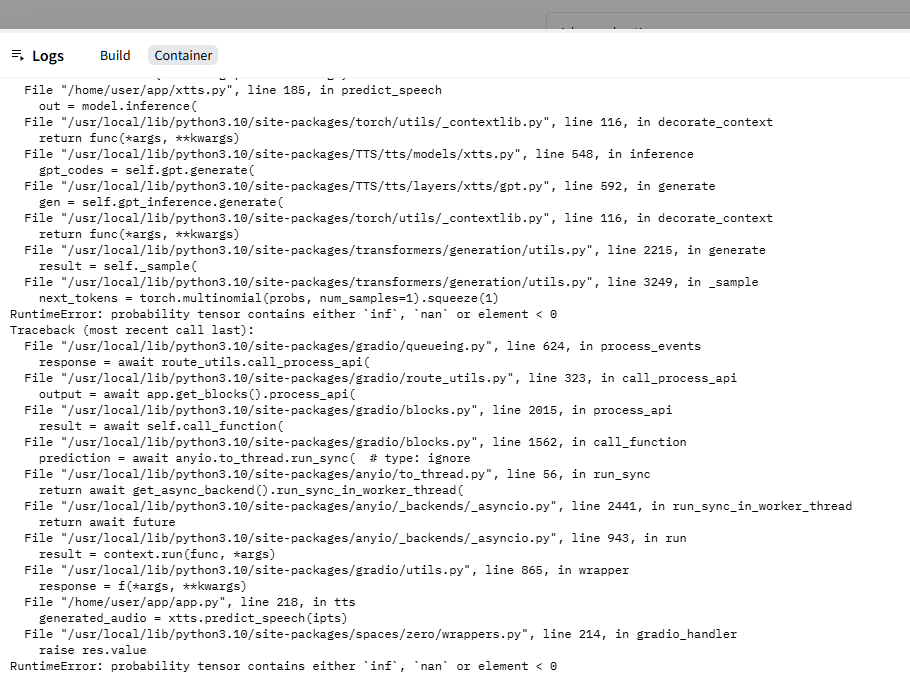
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/spaces/zero/wrappers.py", line 256, in thread_wrapper
res = future.result()
File "/usr/local/lib/python3.10/concurrent/futures/_base.py", line 451, in result
return self.__get_result()
File "/usr/local/lib/python3.10/concurrent/futures/_base.py", line 403, in __get_result
raise self._exception
File "/usr/local/lib/python3.10/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/user/app/xtts.py", line 185, in predict_speech
out = model.inference(
File "/usr/local/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/TTS/tts/models/xtts.py", line 548, in inference
gpt_codes = self.gpt.generate(
File "/usr/local/lib/python3.10/site-packages/TTS/tts/layers/xtts/gpt.py", line 592, in generate
gen = self.gpt_inference.generate(
File "/usr/local/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/generation/utils.py", line 2215, in generate
result = self._sample(
File "/usr/local/lib/python3.10/site-packages/transformers/generation/utils.py", line 3249, in _sample
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
RuntimeError: probability tensor contains either `inf`, `nan` or element < 0
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/gradio/queueing.py", line 624, in process_events
response = await route_utils.call_process_api(
File "/usr/local/lib/python3.10/site-packages/gradio/route_utils.py", line 323, in call_process_api
output = await app.get_blocks().process_api(
File "/usr/local/lib/python3.10/site-packages/gradio/blocks.py", line 2015, in process_api
result = await self.call_function(
File "/usr/local/lib/python3.10/site-packages/gradio/blocks.py", line 1562, in call_function
prediction = await anyio.to_thread.run_sync( <em># type: ignore</em>
File "/usr/local/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/usr/local/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2441, in run_sync_in_worker_thread
return await future
File "/usr/local/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 943, in run
result = context.run(func, *args)
File "/usr/local/lib/python3.10/site-packages/gradio/utils.py", line 865, in wrapper
response = f(*args, **kwargs)
File "/home/user/app/app.py", line 218, in tts
generated_audio = xtts.predict_speech(ipts)
File "/usr/local/lib/python3.10/site-packages/spaces/zero/wrappers.py", line 214, in gradio_handler
raise res.value
RuntimeError: probability tensor contains either `inf`, `nan` or element < 0Code language: JavaScript (javascript)Este erro só ocorria quando tentávamos usar uma voz clonada, e não uma voz de estúdio.
E, ele ocorria no momento do TTS, não no momento em que se clonava a voz. Em outras palavras, ocorria na função xtts.predict_speech.
Também, em meus testes locais, eu não tinha problemas. Se você olhar nos arquivos, verá que tem um Docker criado. Esse Docker é para quando eu quero testar localmente. Executando ele, não tinha problemas.
E, além disso, a última mensagem da stack referencia um arquivo da lib spaces. Tudo isso me levou a acreditar que a diferença estava em algo relacionado com o ZeroGPU, já que era uma das principais diferenças entre o local.
Como a mensagem mencionava os tensores, e, no stack, a função predict_speech, a primeira coisa que eu resolvi fazer foi incluir um print dos embeddings da voz. Especificamente, eu adicionei o print em dois pontos dessa função:
@spaces.GPU
def predict_speech(parsed_input: TTSInputs):
print("device", model.device)
speaker_embedding = torch.tensor(parsed_input.speaker_embedding).unsqueeze(0).unsqueeze(-1)
gpt_cond_latent = torch.tensor(parsed_input.gpt_cond_latent).reshape((-1, 1024)).unsqueeze(0)
print(speaker_embedding)
print("latent:")
print(gpt_cond_latent)Code language: Python (python)Minha esperança era ver se conseguia confirmar pelo menos algum dos valores do tensor com NaN… E bingo:

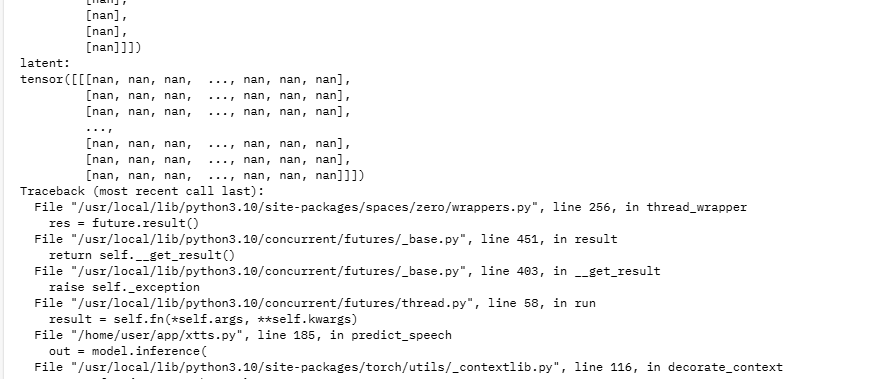
Não só o valor de um dos tensores estavam NaN, como TODOS estavam. Se reparar a função, ela retorna 2 valores que representam os speakers. Ambos são tensores, e estavam todos com NaN. Relembre-se que, no caso da voz clonada, esses tensores foram gerados pela função xtts.predict_speaker.
Então, eu resolvi ir um pouco mais na fonte, e adicionei os prints direto na saída dessa função:
def predict_speaker(wav_file):
"""Compute conditioning inputs from reference audio file."""
temp_audio_name = next(tempfile._get_candidate_names())
with open(temp_audio_name, "wb") as temp, torch.inference_mode():
print("device", model.device)
temp.write(io.BytesIO(wav_file.read()).getbuffer())
gpt_cond_latent, speaker_embedding = model.get_conditioning_latents(
temp_audio_name
)
print(gpt_cond_latent);
print(speaker_embedding);
result = {
"gpt_cond_latent": gpt_cond_latent.cpu().squeeze().half().tolist(),
"speaker_embedding": speaker_embedding.cpu().squeeze().half().tolist(),
}
print(result);
return result;
Code language: PHP (php)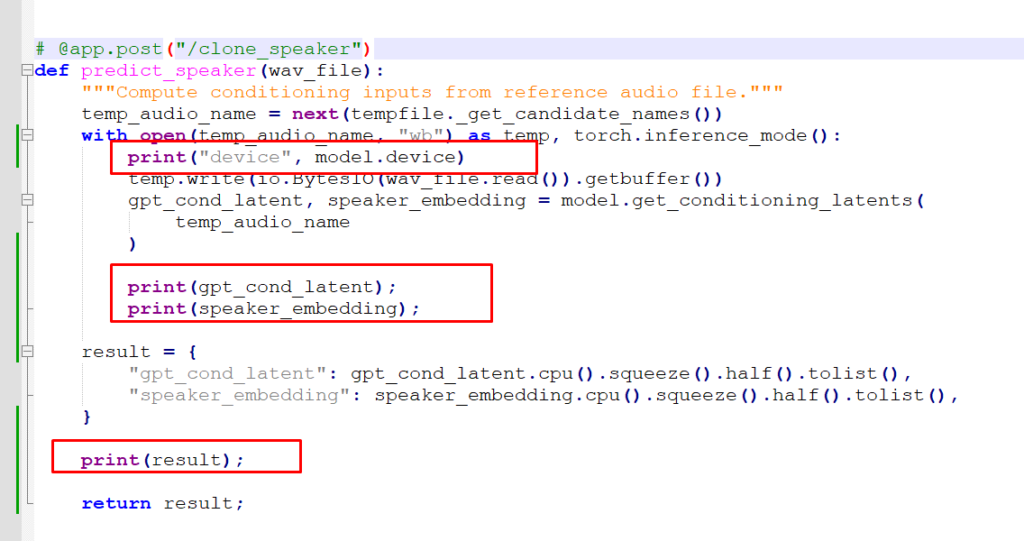
E, novamente, vi que já na saída de model.get_conditioning_latents, os tensores estavam vindo como NaN:

Fui mais a fundo dentro do código fonte do XTTS para entender como isso era feito: https://github.com/idiap/coqui-ai-TTS/blob/2df9bfa78eb338d1b0972c25f4d236403b4e032d/TTS/tts/models/xtts.py#L322
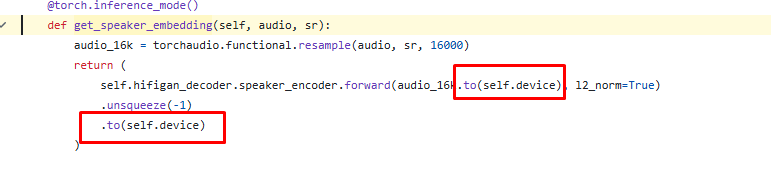
Como os dois embeddings calculados estavam como NaN, fui na speaker_embedding, que é calculada primeiro.
O que essa função faz, basicamente, é converter o sample rate do áudio e invocar um método do objeto hifigan_decoder. Eu não conhecia isso, mas vi que tem esse paper sobre uma rede neural chamada HiFi-GAN: https://arxiv.org/abs/2010.05646. Mas, pela rápida lida, vi que é uma rede para sintetizar fala… O que, obviamente, faz todo o sentido para o clone de voz!
Apesar do meu conhecimento limitado aqui nesse nível, eu notei que nesse ponto, é invocado bastante o método to, para jogar os tensores para um outro device. Isso me fez questionar como esse código poderia estar funcionando, considerando que não há GPU envolvida aqui, e apenas CPU. Então, lembrei de um detalhe simples: a função predict_speaker estava rodando em CPU, e a função predict_speech, em GPU… Imaginei que pudesse haver algum problema de incompatibilidade com isso…
Isso ficou mais estranho, quando eu adicionei logs para ver em qual device o modelo do XTTS foi carregado. Esse é o trecho:
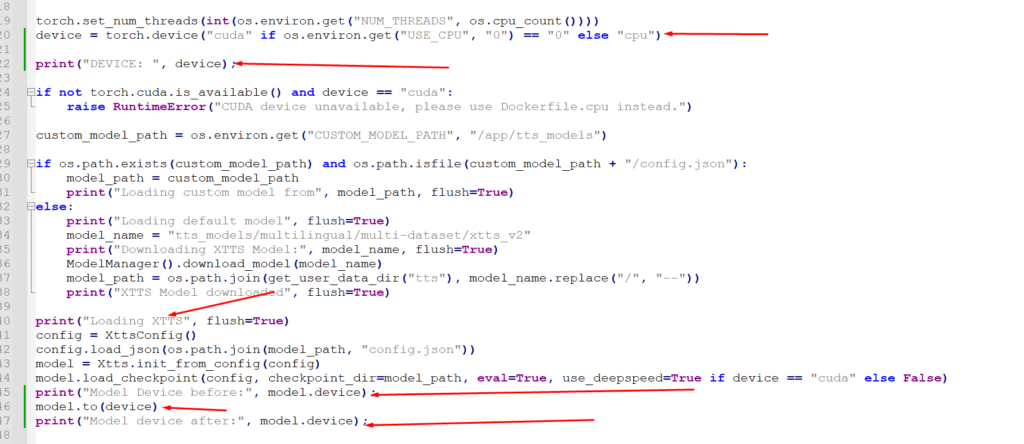
E aqui está o log que foi gerado:
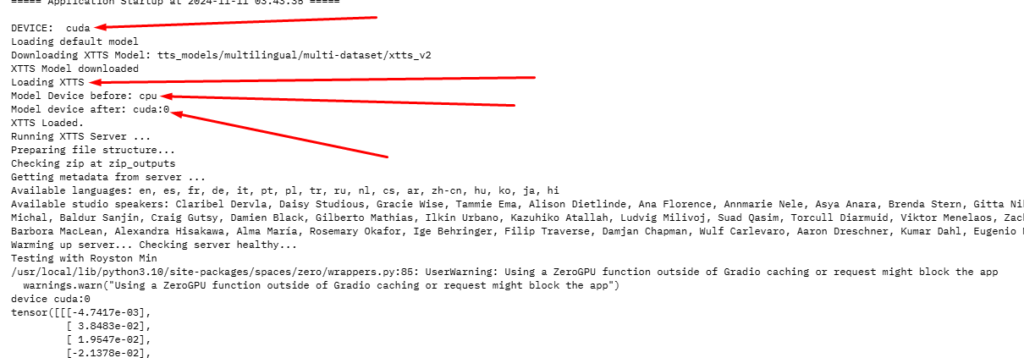
E o que me chamou atenção foi o seguinte:
- A variável
devicecomeça com o valor “cuda”, até aqui, tudo certo, uma vez que essa é a intenção mesmo. - Em seguida, logo abaixo, há um check: se o
cudanão está disponível no torch, gerar um erro…
Mas nenhum erro é gerado…
Significa que, mesmo o código rodando em um Space com ZeroGPU, e sem o decorator, ele detecta que o cuda está sim disponível. - Em seguida, o modelo é carregado, e, como esperado, na CPU. A mensagem “before”, mostra o valor “cpu”.
- Porém, o modelo é movido para o CUDA, e curiosamente, é feito com sucesso… Mesmo sendo um código que roda sem o decorator…
Ou seja, eu não tinha notado isso, mas o modelo carrega tranquilamente na GPU, num Space ZeroGPU sem o decorator… Isso me fez acreditar que, quando uma função que não tem o decorator executa, essas movimentações feitas para um device, podem, de alguma forma, gerar o NaN do tensor.
Eu ainda não descobri exatamente o porquê, e estou fazendo testes neste Space: para tentar simular o cenário. Quando tiver atualizações, eu posto.
Para resolver nesse ponto, eu apenas adicionei o decorator @spaces.GPU na função predict_speaker.
Isso gerou os tensores corretamente…

Porém, ao tentar clonar, um novo erro surgiu…
Problema 2: cannot pickle '_io.BufferedReader' object
Após adicionar o decorator na função xtts.predict_speaker, um erro foi gerado ao tentar clonar:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/spaces/utils.py", line 43, in put
super().put(obj)
File "/usr/local/lib/python3.10/multiprocessing/queues.py", line 371, in put
obj = _ForkingPickler.dumps(obj)
File "/usr/local/lib/python3.10/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
TypeError: cannot pickle '_io.BufferedReader' object
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/gradio/queueing.py", line 624, in process_events
response = await route_utils.call_process_api(
File "/usr/local/lib/python3.10/site-packages/gradio/route_utils.py", line 323, in call_process_api
output = await app.get_blocks().process_api(
File "/usr/local/lib/python3.10/site-packages/gradio/blocks.py", line 2015, in process_api
result = await self.call_function(
File "/usr/local/lib/python3.10/site-packages/gradio/blocks.py", line 1562, in call_function
prediction = await anyio.to_thread.run_sync( <em># type: ignore</em>
File "/usr/local/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/usr/local/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2441, in run_sync_in_worker_thread
return await future
File "/usr/local/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 943, in run
result = context.run(func, *args)
File "/usr/local/lib/python3.10/site-packages/gradio/utils.py", line 865, in wrapper
response = f(*args, **kwargs)
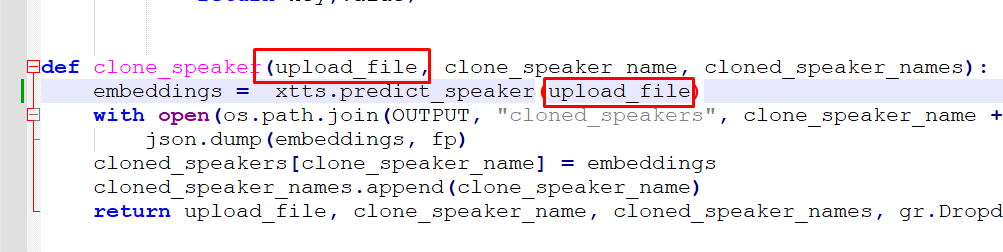
File "/home/user/app/app.py", line 127, in clone_speaker
embeddings = xtts.predict_speaker(open(upload_file,"rb"))
File "/usr/local/lib/python3.10/site-packages/spaces/zero/wrappers.py", line 202, in gradio_handler
worker.arg_queue.put(((args, kwargs), GradioPartialContext.get()))
File "/usr/local/lib/python3.10/site-packages/spaces/utils.py", line 51, in put
raise PicklingError(message)
_pickle.PicklingError: cannot pickle '_io.BufferedReader' object
Code language: JavaScript (javascript)
Este foi o erro gerado quando tentei gerar um áudio usando uma voz clonada.
Agora foi um erro de pickle… Eu não sabia o que era isso, e depois de uma pesquisa, entendi que tinha relação com serialização de objetos, que é um processo que conheço de outras linguagens.
Basicamente, alguma coisa na chamada da minha função não estava conseguindo ser serializada. E, como a única coisa diferente era o decorator, fui olhar novamente o código do decorator, no trecho onde dá o problema:
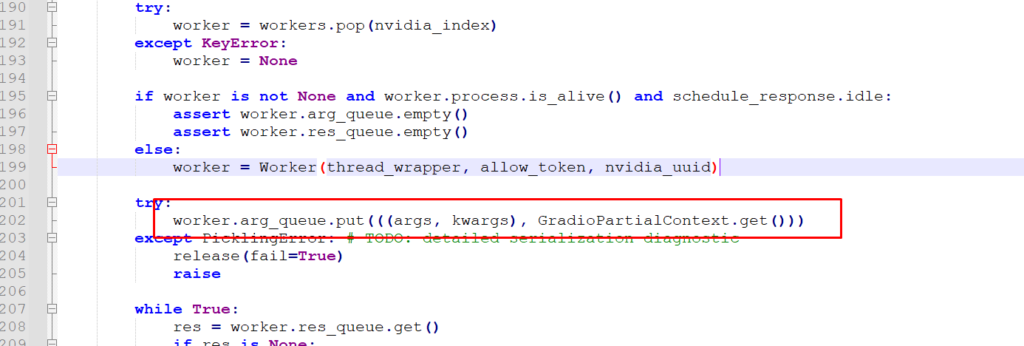
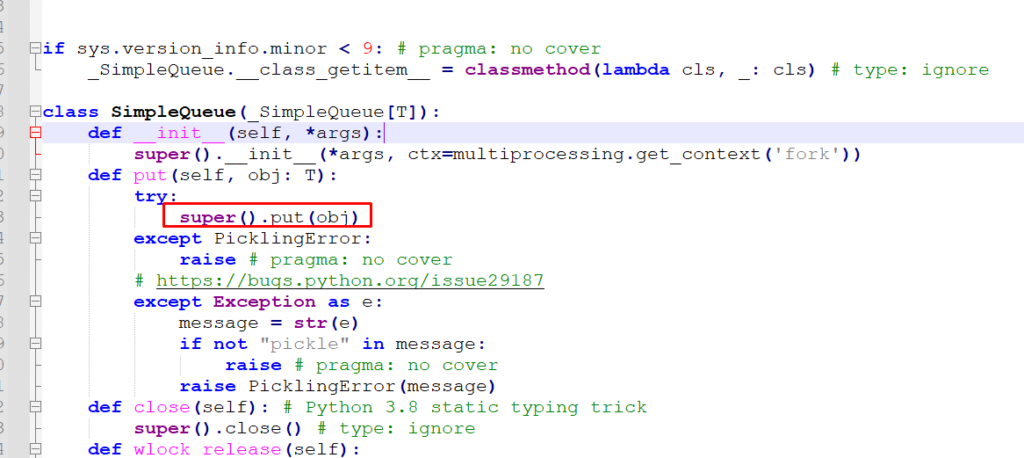
Eu vi que o trecho com problema usava colocava algo em uma fila… E olhando o código dessa fila, que não tinha nada de muito complexo, notei que basicamente ela precisava serializar esses objetos.
Como a mensagem de erro mencionava _io.BufferedReader, e vi que os argumentos são serializados, então, imediatamente me voltei para o parâmetro passado para essa função: wav_file. Esse parâmetro é o arquivo que o usuário informou na interface. Especificamente, o binário do arquivo. Ele é passado dessa forma pela app.clone_speaker:

Ou seja, abrimos o arquivo no modo binário e passamos para a função… Com isso, xtts.predict_speaker recebe um binário. Eu imaginei que, ao invés de passar o binário, pudesse tentar passar o caminho, que seria uma string. Então rescrevi da seguinte forma para manter a compatibilidade:
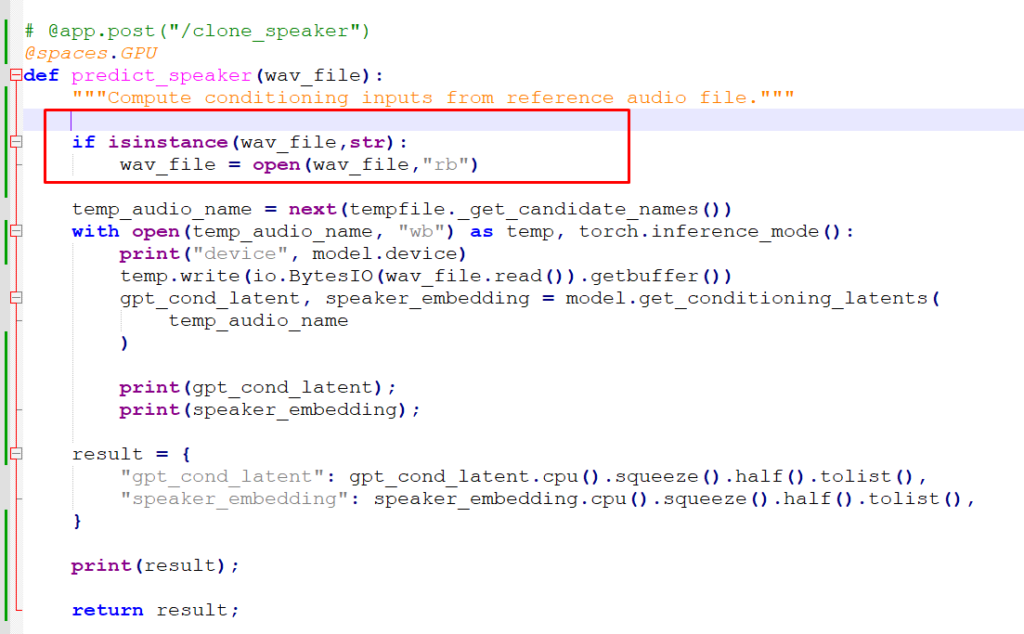
E voilá! O clone passou a funcionar!
Então, em resumo, foram dois problemas:
- Função
xtts.predict_speakernão estava com o decorator do Space, e, por algum motivo que ainda não sei, ao invés do modelo resultar em erros, ou transferir para a CPU, ele gerava tensores com NaN.
Solução: Adicionado o decator@spaces.GPUna funçãoxtts.predict_speaker - Incluir a função no ZeroGPU, causou o erro devido ao tipo do parâmetro;, pois o ZeroGPU faz pickle dos argumentos.
Solução: Passar a string com o caminho do arquivo e abrir dentro da funçãoxtts.predict_speaker.
Comentários finais
E curiosamente, isso me despertou uma nova pergunta: Como o Hugging Face implementa o ZeroGPU? Eu sempre me perguntei se, ele dinamicamente adiciona a placa de vídeo, ou se move a máquina, ou se é um driver customizado que intercepta as chamadas e consegue enviar apenas a requisição para uma máquina com ZeroGPU… Etc.. enfim, muitas perguntas…
Eu criei esse Space: Zero Test – a Hugging Face Space by rrg92
E nele estou fazendo testes para me ajudar a responder todas as perguntas que ainda ficaram. De qualquer maneira, fazer todo esse processo me ajudou a aprender muito mais sobre Python, PyTorch, Hugging Face, ZeroGPU e o XTTS. Já valeu a pena!
Quando eu tiver mais respostas, eu atualizo esse post e/ou posto um novo!
Muito obrigado pela sua leitura! Até a próxima!
Apaixonado por tecnologia e veterano em bancos de dados SQL Server, este entusiasta agora se aventura no fascinante universo da Inteligência Artificial.
Atualmente é o Head de Inovação da Power Tuning, onde é o responsável por trazer novas ideias para produtos e serviços, que melhorem a produtividade do time ou a experiência do cliente! Com muita experiência em programação, hardware, sistemas operacionais, e mais, agora quer juntar tudo isso nesse novo mundo e trazer muitas ideias e conhecimento sobre Inteligência Artificial!
Neste blog, vai compartilhar sua jornada de aprendizado e uso da IA, focando em como transformar nossa maneira de resolver problemas e inovar.
Contents




