Canal Youtube
Canal YoutubeEnglish Version on Simple Talk | English Short Version on Azure blog
Uma lembrança muito forte que tenho é do meu pai e sua maleta de ferramentas, com todo tipo de ferramenta para os mais variados reparos que eram necessários em casa. As vezes, ele passava vários minutos procurando um parafuso específico para algo que precisava resolver. Ao longo dos anos, ele foi juntando e montando a sua maleta com diversas ferramentas que sempre o ajudavam!
Com mais 10 anos de DBA SQL Server, eu fiz a mesma coisa. Juntei um bocado de scripts SQL que me foram me ajudando em diversas situações. Neste ano, eu resolvi compartilhar esses scripts nesse repositório git: https://github.com/rrg92/sqlserver-lib.
Mas eu sempre tiver a mesma dor do meu pai: as vezes, passava um bom tempo procurando o script adequado para alguma necessidade no ambiente que eu gerenciava ou em alguma consultoria.
E, graças a IA, essa dor finalmente pode ser resolvida. Eu fiz uma ferramenta que usa IA para procurar o melhor script para alguma necessidade que eu precisar. Com isso, fica muito mais fácil e rápido achar algo ai no meio de tanta coisa que já tem e que eu ainda vou colocar lá: Demonstração de IA que ajuda e encontrar scripts SQL em repositório GIT
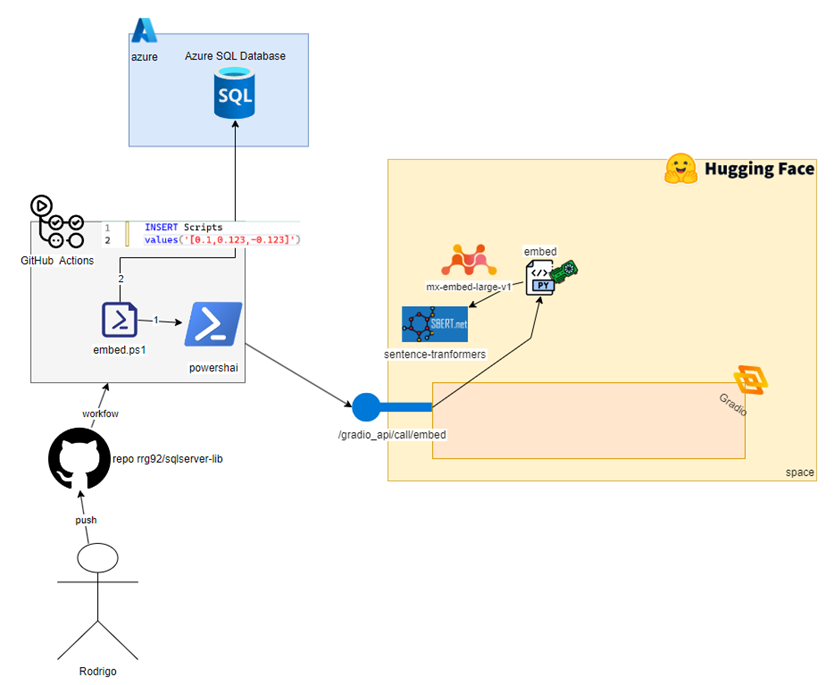
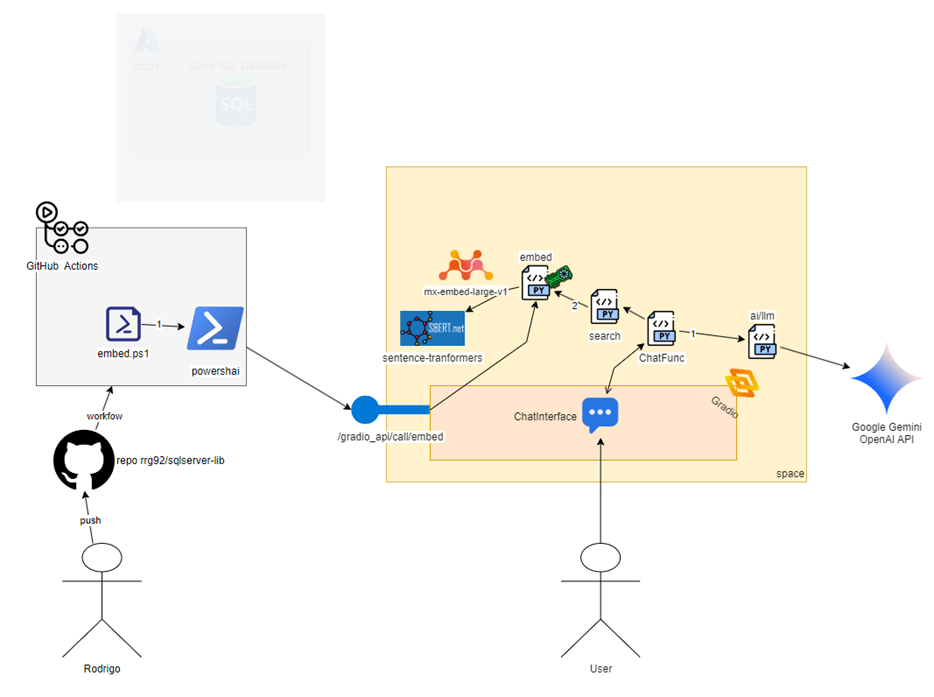
Esse é o diagrama completo de tecnologias que eu sei para fazer isso:

Nesse post eu quero explorar no detalhe isso e vamos reconstruir cada pedaço dessa imagem para que você entenda como tudo foi feito!
Ao final desse post, você terá compreendido como construir um pequeno projeto de RAG usando as novas funcionalidades de IA do SQL Server, python, Hugging Face e o Gemini. Volte nessa imagem para ver o quanto de coisa você aprendeu.
Dividir para conquistar
Usar IA para auxiliar na pesquisa envolve 2 fases principais: indexar o conteúdo e a busca em si.
Eu preciso indexar o conteúdo para que eu consiga achar fácil o que é relevante para o texto do usuário. Por exemplo, se ele procurar por “problema de performance” eu preciso achar os scripts para checar performance de CPU, validar o que está em execução, etc. Não preciso, por exemplo, de um script para recriar constraints.
Então, uma vez que eu tenho isso em um banco de dados, quando o usuario de fato fizer a pergunta, eu preciso ir nesse banco, buscar o que é relevante e usar alguma modelo de linguagem (LLM) para apresentar e explicar esses resultados. Tudo isso junto é o que chamamos de RAG
Então, para que você compreenda melhor eu vou dividir esse post em 2 partes, uma explicando a parte de indexação dos dados e a outra a parte de busca.
Fase 1: Indexando os dados
A primeira coisa que preciso para um projeto como esse é indexar os meus scripts. Mas, não é apenas pegar o conteúdo do arquivo e jogar em um banco para fazer um LIKE ou um FullText. Lembre-se que precisamos suportar pesquisa pelo significado. Se eu procurar por um texto “problema de performance”, então a busca deve achar todos os scripts que falam de requests, de identificar CPU, etc.
Nesse mundo da IA tem um conceito chamado embeddings. Eles são uma representação numérica do significado de um texto. Aqui nesse post eu faço uma introdução sobre embeddings para que você entenda melhor como isso ajuda nisso. Mas, basicamente, eu preciso gerar os embeddings dos meus scripts e jogá-los em uma tabela do banco. O script que faz isso é o embed.ps1.
Esse script é invocado via gitHub Actions toda vez que eu faço um push com uma tag no formato embed-*. Com isso eu controlo quando eu quero atualizar o banco.
Vamos reconstruir nosso diagrama incial, mostrando esses componentes vistos até aqui:

Primeiro uso de IA: Gerando os embeddings dos scripts
Se você pensou que usaríamos IA somente para gerar texto, aqui vai a primeira surpresa. IA vai muito além de gerar texto e no nosso projeto o primeiro uso é para gerar a representação numérica do nosso texto, os famosos embeddings. Isso nos permite fazer buscar pelo significado posteriormente no SQL Server (graças ao novo suporte de IA que vai vir no 2025).
Para cada arquivo do repositório eu vou gerar os embeddings dele usando um Space do Hugging Face que eu criei. Mais adiante eu vou falar mais desse Space, mas por o que você precisa saber agora é que, basicamente, ele é uma aplicação python, que usa um framework chamado Gradio, que facilita MUITO minha vida ao construir toda essa interface web e APIs… O Gradio é voltado pra esse mundo de IA e é cheio de componentes fáceis de usar que fazem tarefas relacionadas a esse mundo de Machine Learning…
Se você olhar no arquivo embed.ps1, vai ver que uso uma função chamada GetEmbeddings. Esta função está definida no arquivo util.ps1. Ela usa o powershai, que tem uma das facilidades que eu mais gosto: Consigo invocar a API do Gradio como se fosse uma função powershell. Com isso, eu consigo invocar um serviço para gerar embeddings usando o próprio space que eu criei. Só precisei expor ele via API.

Aqui está o nosso diagrama atualizado com todo esse fluxo:

Inserindo os dados no SQL Server
Até aqui, você viu como calculamos os embeddings dos scripts. Mas ainda sim, precisamos salvar isso num banco que consiga me ajudar a usar essas informações. É aqui que entra o SQL Server 2025 e seu novo suporte a IA: Agora ele tem um tipo de dados chamado vector, que é justamente para receber esse tais embeddings. E junto com esse tipo, algumas novas funções foram adicionadas e me permitem fazer algumas operações com eles. Vamos ver isso na prática. Para este projeto, eu estou usando o Azure SQL Database,que é muito barato para subir e já tem estes mesmos recursos que iremos usar (enquanto o SQL 2025 ainda está em public preview).

Começando, essa é a definição da tabela onde iremos guardar os scripts (tab.Scripts.sql):

Uma breve explicação dessas colunas:
- id é um número unico que vai ser gerado pra cada arquivo
- RelPath é o caminho relativo a raiz do projeto no GitHub
- ChunkNum é o número de parte do arquivo. Em arquivos muito grandes, eu poderia quebrar em partes menores, já que os modelos de IA podem não conseguir processar tudo. Então aqui eu iria inserir uma linha para cada parte (de cada arquivo). Porém eu não implementei isso ainda, mantendo as coisas simples. Logo, isso sempre vai ser 1.
- ChunkContent é o trecho do arquivo. Como não implementei ainda essa quebra, então, vai ser sempre o conteúdo inteiro
- embeddings é a novidade: É aqui que vamos armazenar os embeddings que o modelo de IA vai me retornar, para que eu posteriormente possa buscar. E, de novo, como eu não implementei nenhuma quebra, será os embeddings do conteúdo inteiro do arquivo. No futuro, será o embeddings referente apenas aquela parte.
Uma vez que eu calculei todos os embeddings, agora eu posso inserir no banco. Aqui eu tenho várias abordagens que poderia usar: A cada embedding calculado, inserir no banco, calcular tudo de uma vez e inserir no banco no final, inserir somente o que foi alterado de um commit para outro, etc.
Para essa primeria versão, eu optei por fazer um loop, calcular todos os embeddings de todos os arquivos, e no final, fazer TRUNCATE TABLE e um BULK INSERT. A principal desvantagem disso é que se um dos embeddings falha, eu perco todo o resto e tenho que recomeçar tudo de novo. Em futuras versões, eu vou melhorar isso. Por ora, para poucas linhas (menos de 600) isso funciona bem.
Portanto, após o loop, eu faço isso:

Dbulk é apenas uma função auxiliar definida no script util.ps1 que usa as bibliotecas nativas do .NET para conexão com o SQL Server (Está em deprecated, mas ainda funciona. Futuramente posso atualizar para a nova biblioteca). A função obtém os dados de conexão de variáveis de ambientes configuradas no git, que são só acessíveis ao rodar o pipeline.
E esse é o nosso diagram atualizado (no diagrama eu deixei um INSERT … VALUES, apenas por questão de espaço. O real é mesmo é TRUNCATE + BULK INSERT).

E aqui temos a nossa primeira fase completa. Há muitas melhorias para fazer no futuro: poderia quebrar os scripts em partes menores, extrair os comentários e indexar separadamente, padronizar o texto dos comentários para o inglês (que tende a ser melhor para a busca). Mas, mantive a simplicidade nessa primeira versão, e, como mostrei no vídeo acima, atende bem. Em futuras versões, dá pra explorar muito mais técnicas aqui!
Aqui vai um resumo do que fazemos aqui na fase de indexação:
- Quando eu faço um push no meu repositório git (adicionando ou alterando scripts), isso dispara um workflow, definido no arquivo embed.yml
- Esse workflow via carregar uma imagem docker do powershell que roda o arquivo embed.ps1
- O embed.ps1, vai iterar em cada arquivo, e usando o módulo PowershAI, conectar com o space do Hugging Face que eu criei e gerar os embeddings usando GPU lá da infra do Hugging Face
- Após todos os embeddings gerados, a tabela Scripts que fica em um Azure SQL Database vai ser truncada e em seguida faço um BULK INSERT, inserindo todos os dados dos scripts, incluindo os embeddings gerados!
Fase 2: Pesquisando
Agora você já sabe como indexamos os scripts, chegou a parte mais mágica: Como eu faço uma busca semântica e gero uma resposta com base nesses dados?!
Essa parte é quase toda no Space do Hugging Face usando python e uma parte indo ao SQL Server.
O Space do Hugging Face
Tudo começa quando o usuario digita uma mensagem na inteface do chat. Vamos agora observar o diagrama com apenas o que precisamos para a fase 2:

A área em amarelo representa o space Hugging Face que eu criei. Isto é, a fase de pesquisa começa lá, com o usuário abrindo a interface de chat e enviando uma mensagem. Se você for lá no space que eu criei e clicar na aba Files, vai ver todo o código que uso para subir esse space (os Spaces do Hugging Face são repositórios git também):

O arquivo que dá vida ao space é esse app.py. Ele é quem é executado para subir essa interface que você acessa. Vamos começar por ele, explicando onde tudo começa.
Ponto de partida: Interface do Chat no Hugging Face
Conforme mencionado anteriormente, a Interface é construída com a biblioteca Gradio. Ela é voltada para construir aplicativos de Machine Learning. Ela contém diversos elementos comuns ao mundo de IA, e por isso é amplamente integrada ao Hugging Face (que é dona da startup Gradio). Eu gosto bastante dela pela facilidade em integrar esses elementos visuais comuns ao mundo de IA.
Criar a interface para o chat, e a tabela que recebe os dados é extremamente simples. No início do script eu importo a biblioteca:

E lá embaixo, é onde eu defino a interface de Chat: Cerca de 10 linhas de código. Quem conhece de programação web, sabe o quanto é complexo criar isso do zero. Então, obrigado time do Gradio! Isso me poupa muito tempo e me permite focar mais nos modelos de Ia e solução, do que em elementos visuais.
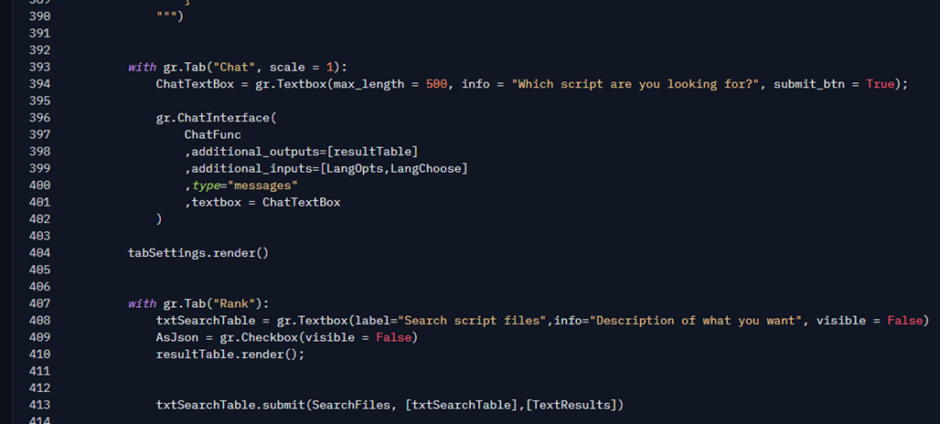
A classe gr.ChatInterface é o ponto central aqui. Basicamente, ela constroi toda quela interface do chat, e, quando o usuário envia uma mensagem, ele invoca a função que passamos no primeiro parâmetro: ChatFunc. É nela que eu defino toda a lógica principal que vai guiar a IA para gerar a resposta que o usuário está pedindo.
A Função ChatFunc
Quando você digita o texto na interface e envia a mensagem, a função Chatfunc é invocada. Está é uma função que eu criei nesse mesmo script.
Essa função define alguns elementos para conseguir interagir com a interface de chat, como a mensagem atual, histórico e outros parâmetros que eu posso passar, neste caso, o idioma detectado ou escolhido pelo usuário.

Aqui está o diagrama atualizado até aqui:

Segundo uso de AI: Traduzindo a mensagem do Usuário
Aqui é o segundo ponto do nosso projeto onde usamos um modelo de AI. Agora, vamos usar um modelo de linguagem mesmo, porém, não vou rodar no próprio código, e sim invocar uma API.
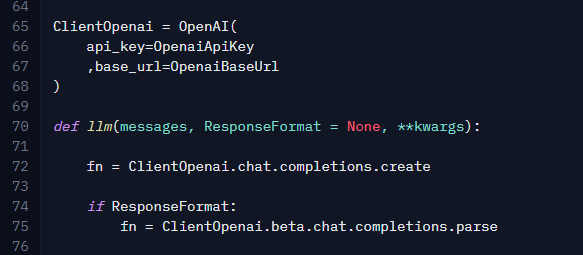
Eu criei uma função chamada ai. Esta função invoca envia uma requisição para uma API compatível com a OpenAI. No final, ela acaba usando a biblioteca python da OpenAI mesmo.
No caso, a primeira execução dela pede uma tradução do texto do usuario pro ingles.

Por que isso? Após testes vi que o modelo que uso nos embeddings se sai muito bem com ingles. Então, resolvi usar o texto ingles para fazer a busca. Graças as IAs, fazer isso é bem fácil e tranquilo. Aqui é o primeiro uso da API do Google que faço.
Aqui eu aproveito para identificar o idioma do texto de origem. No final, a variável Question vai ter o texto traduzido e SourceLang o idioma escolhido automaticamente (se o modo automático está habilitado na aba Settings). Eu poderia subir um modelo menor, nesse proprio script para fazer a traducao, mas optei por nao fazer apenas para deixar o código mais simples. Talvez uma melhoria futura aqui.
Caso tenha curiosidade, a funcao ai é apenas uma facilidade para que eu possa chamar a biblioteca da openai de uma maneira mais flexível:

Na verdade, são duas funções que eu criei pra isso: ai e llm. O objetivo da ai é apenas me permitir passar um system prompt, user prompt e um formato esperado. No final, ela chama a função llm, e a função llm cuida de chamar a biblioteca da openai e lidar com o resultado.
Como pode ver, eu estou usando o Google Gemini. Poderia usar qualquer modelo compatível com essa biblioteca:

Aqui está o nosso diagrama atualizado com esse processo:

Terceiro uso de AI: Gerando embeddings novamente
Seguindo o código, o próximo trecho relevante é a função search (ainda dentro de ChatFunc). É aqui que vamos novamente usar um modelo de IA que já é nosso velho amigo.

Search é uma função que basicamente conecta no SQL Server e obtém os scripts mais relevantes para um texto passado como parâmetro. Vamos explorar-lá nos detalhes

Vamos lembrar o que aconteceu até aqui:
- O usuário digitou uma mensagem (pedindo um script que quer procurar)
- Usamos a API do Google Gemini para identificar o idioma dessa mensagem original e também para traduzir pro inglês
- Chamamos a função search, passando o texto traduzido.
A primeira coisa preciso fazer é obter os embeddings desse texto traduzido. Aqui eu uso a função embed que você conheceu anteriormente. Note que é exatamente a mesma função que uso lá na fase 1 para indexar. Vou colocar o diagrama com esse trecho da fase 1 para você se situar:
Isso é muito importante, pois para que todo esse processo funcione bem, você precisa gerar os embeddings usando o mesmo modelo e parâmetros que gerou para indexar. Gerar embeddings com um modelo ou configurações diferentes, pode fazer com que o resultado seja muito ruim, trazendo um conteúdo que não tem absolutamente nada a ver com o texto. A diferença aqui é que, ao indexar, eu chamo a função via API e aqui, na fase de pesquisa, eu a chamo direto, já que está carregada no mesmo código que gera a interface.
Bom, voltamos ao diagrama, olhando somente o lado da pesquisa:

A função Embed
Finalmente, vamos conhecer como a função embed funciona… E ver o código de um modelo de IA em ação!!!

Decepcionado? Não era bem o que esperava né? Poderia esperar 3 mil linhas de código, afinal, estamos falando de invocar um modelo de IA… Mas, se eu tivesse que fazer toda a lógica aqui para executar um modelo de IA, essa função com certeza teria milhares ou milhões de linhas de código…
Tudo aqui se resume a chamar o método encode, do objeto Embedder, que foi definido aqui:

Embedder é variável que aponta para um modelo de IA usando a biblioteca Sentence Transformers (não me julgue pela escolha do nome da variável,ok?). Com o Sentence Transformers, eu consigo carregar diversos modelos disponíveis no Hugging Face e fazer algumas operações que usam esses modelos. Sim, graças a bibliotecas como o Sentence Transformers, trabalho da comunidade open source, usar IA é tão simples quanto invocar funções… Por trás desse método encode, há uma série de bibliotecas sendo chamadas, como a Transformers, que por sua vez chamam outras, como PyTorch, que são quem fazem o “trabalho sujo” de coordenar a execução na GPU, implementar as arquiteturas de redes neurais, etc.
Note o nome mixedbread-ai/mxbai-embed-large-v1. Esse é o modelo que escolhi usar para gerar esses tais embeddings. Como e porque eu escolhi isso? Notou que falei que invocar a IA é tão simples como invocar método né? Sim, invocar é fácil, o difícil é determinar qual a melhor a IA para ser usada em meio a milhares de opções. Eu fiz vários testes com outras e cheguei a conclusão que esse modelo me atendeu muito bem para a pesquisa, por isso resolvi usá-lo.
Se você quiser ver mais detalhes do modelo, é so acrescentar https://huggingface.co antes do nome, ficando assim: https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1
Assim você cai na página principal do modelo, que está hospedado aí no Hugging Face. Do monte de informacoes que tem aí, uma das mais importante é saber o número de dimensões que o modelo vai gerar. A partir da página principal acima, eu cheguei nessa.
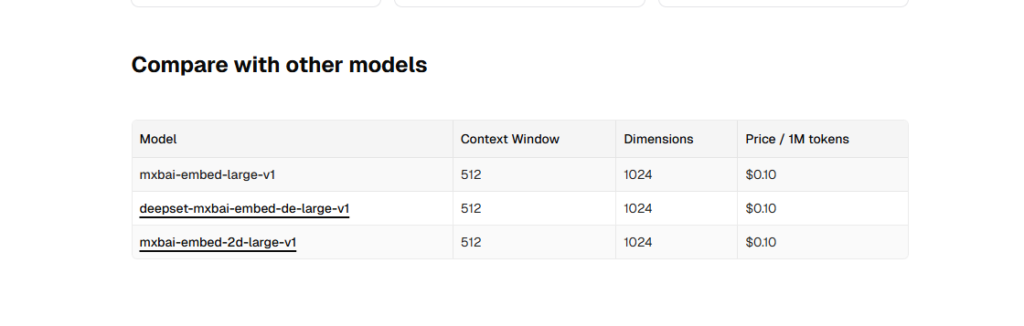
Aqui é onde eu achei o número de dimensões que esse modelo gera. Eu preciso saber disso, pois vou precisar dessa informação ao criar minha tabela que vai guardar os scritps, lá no SQL Server. No caso desse mxbai, ele gera embeddings de 1024 posições, e por isso que no arquivo tab.Scripts.sql, usamos o tipo de dados vector(1024). Quanto maior o número, mais espaço ocupa. E o modelo tende a ser mais preciso nessas representações, mas isso nem sempre é uma relação direta. Só os testes e experiência vão te guiar aqui.
Usando GPU
Voltando a função embed, note mais um detalhe: Ela tem o decorator @spaces.GPU.

Com esse comando, eu estou dizendo ao Hugging Face que essa função deve rodar em uma GPU. Isso é parte do recurso ZeroGPU, onde o Hugging Face permite que eu use GPU poderosas (por um custo muito pequeno, comparado ao que você encontra ai no Azure ou Amazon, por exemplo). Eu digo que é um custo pequeno porque eu preciso ter a conta PRO (custa 9 dolares), e ai posso usar isso.
Porém, isso tem um problema: O Hugging Face limita o consumo de GPU por usuário. Se você tentar usar o space sem logar, ele usa o seu endereço de IP para aplicar os limites. Como o seu endereço de IP pode ser o mesmo para outros usuário da mesma região (cidade, estado, país etc.), você pode acabar tendo limites por conta de outros usuários que chegaram com o mesmo IP. Se você receber algum erro de uso que fala sobre GPU (ou um erro genérico), me avisa nos comentários que posso avaliar (dependendo da quantidade de gente que me pede) fazer um upgrade de GPU.
Graças a GPU, a função embed roda muito rápido. Mesmo parecendo simples, atrás daquela simples função, tem muito processamento rodando e a GPU faz muita diferença. Para você ter ideiada difereça, eu criei um outro space com o mesmo código, mas que não tem GPU associada: Sqlserver Lib Assistant – a Hugging Face Space by rrg92. A vantagem desse space é que ele não limites, e desvantagem é que é muito mais lento.
O seguinte código powershell mostra isso
# instalar o powershai se nao estiver instalado
install-module powershai -Scope CurrentUser
import-module PowershAI
# Ativar a conexao com o hugging face
Set-AiProvider HuggingFace
# Abrir a conexao com o space
# Vamos usar a versao de CPU
Get-HfSpace rrg92/sqlserver-lib-assistant-cpu
# Cria funcoes que comunicam com a api do Hugging Face;
# esse comando vai criar uma funcao para cada endpoint disponiveil e o nome da funcao vai começar com IaTalking
New-GradioSessionApiProxyFunction -Prefix IaTalking
# Como eu tenho uma funcao chamada Embed, posso usar simnples assim:
IaTalkingEmbed 'IA Talking, o melhor blog de IA!'
Code language: PowerShell (powershell)Busca com Embeddings
Agora que temos os embeddings do texto do usuário, e temos os embeddings dos scripts salvos em um banco de dados, podemos fazer a famosa busca semântica, isto é, buscar pelo significado.
Para conectar com o SQL, eu uso a biblioteca pymssql, e as configurações e conexão vem de variáveis de ambiente (que só eu consigo ver nas configurações do space):
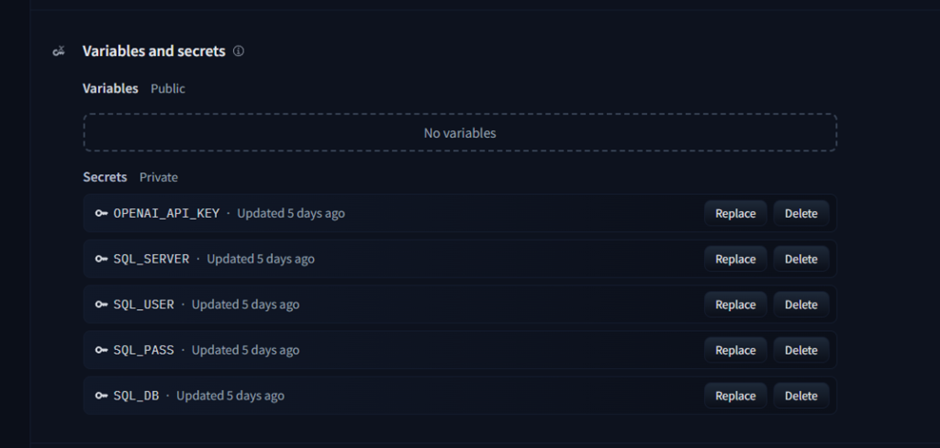
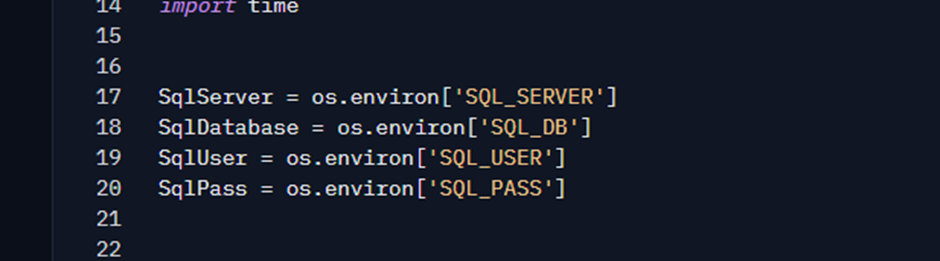
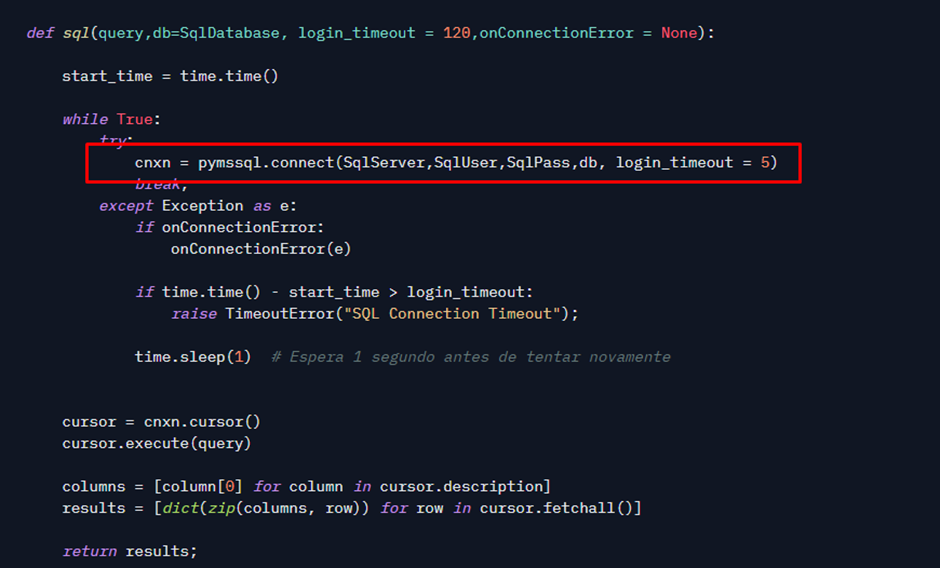
Diferente de um LIKE ou Full Text, onde você passa um texto a ser buscado em um filtro Where, aqui a abordagem que vamos usar é um pouco diferente:

Aqui está o diagrama (adicionamos o caminho com o número 3):

O Script T-SQL para a busca
Note que no início do Script eu declaro uma variável com o tipo vector. Esse é o novo tipo de dados do Azure SQL Database que me permite armazenar os embeddings (e veio no SQL 2025 também). O valor dessa variável SQL vem da variável python que contém os embeddings, resultado da função embed. Quando eu concateno na string, ele já converte automaticamente para a representação em JSON de array de floats, que é o formato literal que o SQL Server espera para esse tipo de dado.
Seria o mesmo que eu fizesse assim:

Voltando a query do script, note que eu declarei como 1024, exatamente com o mesmo tamanho declarado na coluna. E aqui reforço: Os embeddings precisam ser gerados da mesma forma que foi pra indexar, o que inclui ser o mesmo modelo e TAMANHO.
Vamos isolar cada trecho do SELECT. Começando pelo select mais interno:

Aqui eu estou fazendo um SELECT na tabela scripts e gerando uma coluna com o nome CosDistance.
VECTOR_DISTANCE é uma função que aceita 2 embeddings e retorna um valor entre 0 e 2. Quanto mais próximo de 0, significa que ambos os textos respectivos a esses embeddings são semanticamente iguais. Essa métrica é chamada Cosine Distance.
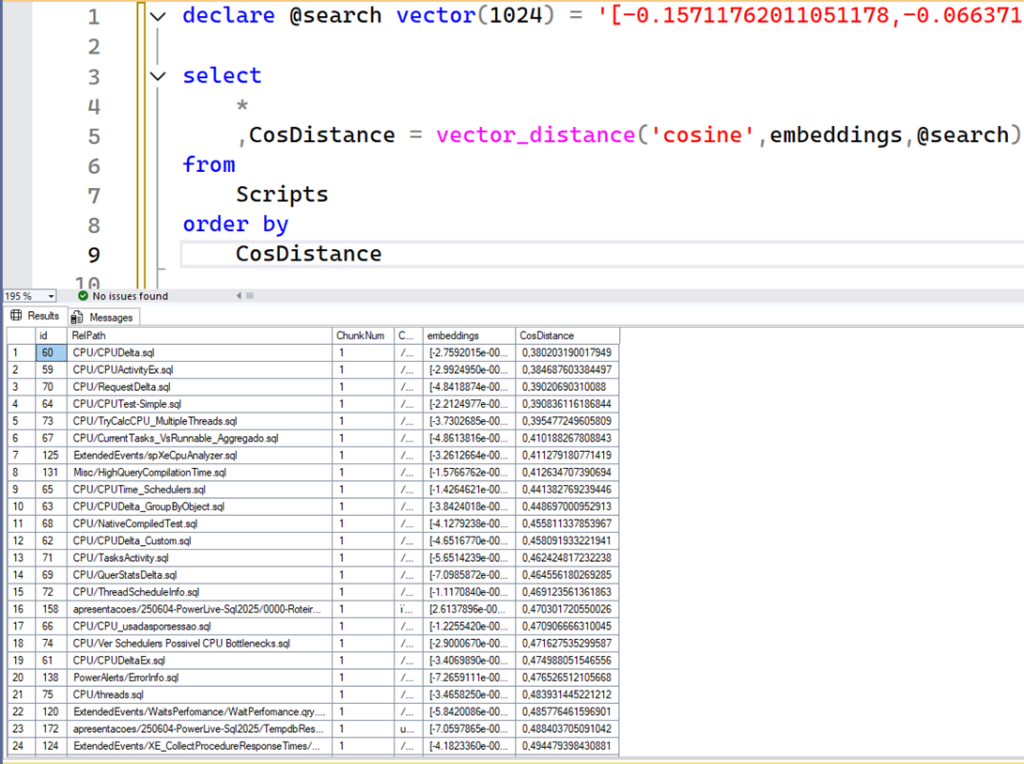
Vamos ver um resultado de exemplo desse trecho quando eu procuro pelo texto ‘cpu performance’. Vou colar os embeddings diretamenteno código, como se fosse o Python fazendo:
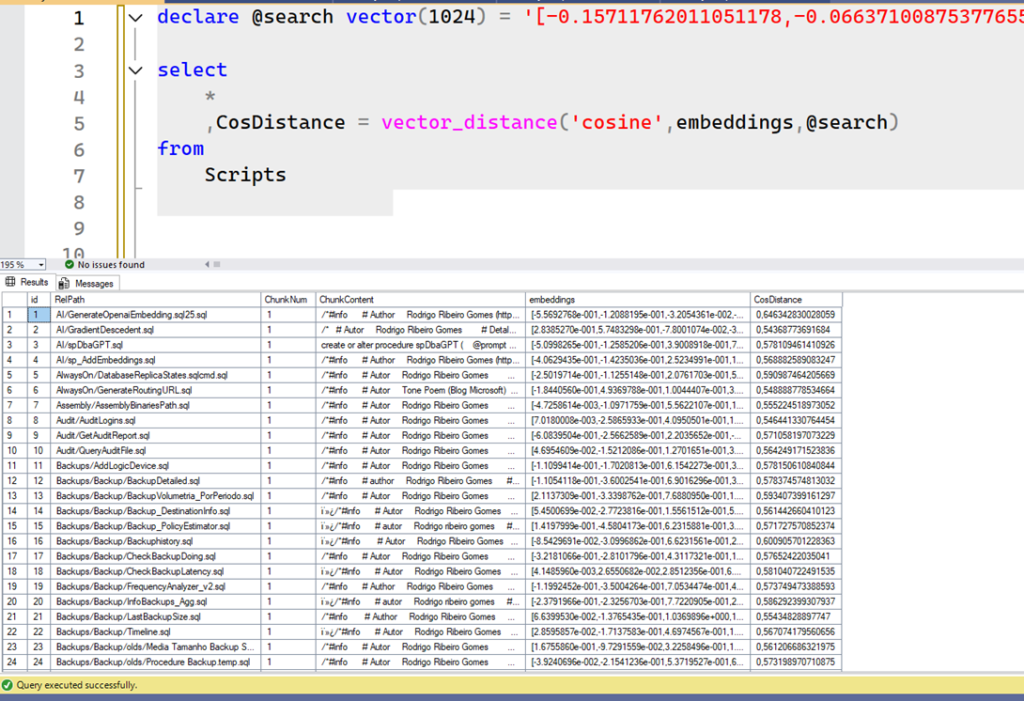
O resultado acima é de um SQL Server 2025 Public Preview, onde eu carreguei as tabelas eos scripts com os embeddins. Sem qualquer ação adicional, não temos nada útil nesse resultado. Note que a coluna CosDistance contém valores diferentes e algumas linhas estão com o valor mais próximo de 0 do que outras. Esta é a razão pela qual eu preciso ordenar pela coluna CosDistance, que é o que fazemos na query de fora. Lembre-se que quanto mais próximo de 0, mais semelhante os resultados são do texto que originou esses embeddings, e como nós queremos os mais semelhantes possíveis, basta ordenar. Aqui é o mesmo resultado, porém ordenado:
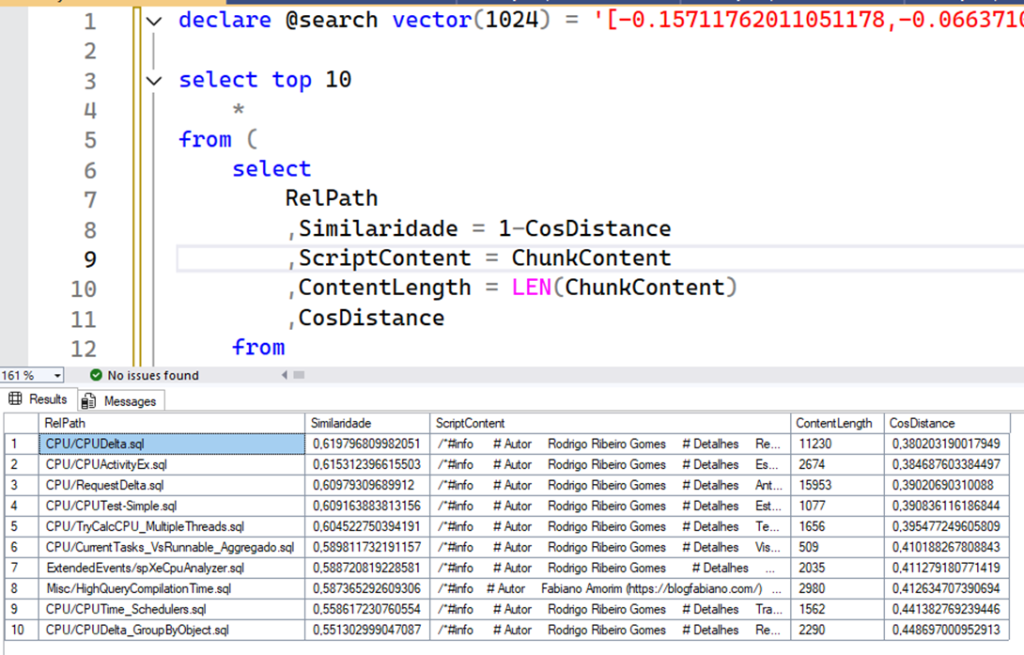
Veja como após o order by, as primeiras linhas tem muito mais relação com CPU do que do resultado anterior (que trouxe scripts relacionados a Backup, ou AlwaysON).
Perceba que no script mais externo eu faço um TOP … ORDER BY CosDistance, pois eu quero retornar só os TOP X mais parecidos. Aqui caberiam algumas outras otimizações que eu não implementei por simplicidade: Poderia colocar um threshold mínimo (ex.: somente CosDistance <= 0.2 por exemplo), poderia tentar incorporar um fulltext para checar algum termo, etc.
Um outro ponto importante é que se minha tabela de Scripts tivesse 10 milhões de linhas, dessa maneira que eu fiz seira extremamente ineficiente, pois o SQL teria que ler todas as linhas, calcular o VECTOR_DISTANCE de todas elas, ordenar tudo isso (provavelmente causando uso do disco) e no final me trazer uma pequena parcela. Seria uma query destruidora de recursos.
É aqui que entra uma funcionalidade INCRÍVEL que foi anunciada também e provavelmente teremos em breve no Azure SQL e no SQL 2025: VECTOR INDEX. Poderemos criar um índice especial nessa coluna embeddings que otimizaria essa busca, e ele não precisaria ler os 10 milhões. Mas, por enquanto, para meu conjunto de dados que é extremamente pequeno, fazer o scan não ainda não representa um problema significativo.
Um outro trecho de destaque é esse:

Aqui é onde eu calculo algumas coisas interessantes, como o quantidade de caracteres do meu script e a Similaridade (Similaridade por Cosseno). Esse é um valor entre -1 e 1, e quanto mais próximo de 1, mais os valores são parecidos. É apenas um cálculo derivado do Cosine Distance.
Esse trecho será usado na exibição e também para input para que outra IA possa analisar os resultados. Este seria o resultado retornado ao python:
Depois que a query roda, eu retorno os resultados de volta pra nossa ChatFunc:
Quarto uso de IA: Rerank
Até aqui, a nossa função search fez o trabalho principal: Achar os scripts que mais possuem relação com o texto do usuário.
Porém, os embeddings não são perfeitos. Eles podem achar mais coisas que deveriam. E isso é completamente normal, pois depende do treinamento de cada modelo, que obviamente não cobre todos os casos. Ele poderia achar que o Script A seja mais próximo do meu texto do que o Script B, quando na verdade, poderia ser B o script mais adequado.
Para esse caso, temos uma segunda técnica muito importante e efetiva: RERANK. O rerank usa um modelo de IA para calcular um score que indica o quanto dois textos são parecidos.
Até aqui, nós fizemos isso através de embeddings: Geramos separadamente os embeddings e comparamos os embeddings para ter um valor de proximidade. O Rerank é um processo parecido, mas ao invés de comparar os embeddings, você compara os textos diretamente. Isso melhora os resultados significativamente.
Esse é o trecho que faz isso:

Siga agora o caminho 4 no nosso diagrama:

Primeiro, eu preciso separar o conteúdo dos scripts. A variável doclist vai é um array de string, onde cada item é conteúdo do script que nossa query achou com a busca pelos embeddings. Em seguida, eu chamo a função rerank, que é quem de fato calcula o score. Note que eu passo o texto (em inglês) e a lista com o conteúdo dos scripts. O resultado da função vai ter o índice do documento e o score, o que eu uso de volta para adicionar na nossa variável FoundScripts.
A definição de rerank é bem simples:

Eu coloquei esse trecho simples em uma função separada por um motivo muito simples: Usar GPU!
Eu não preciso de GPU para chamar APIs do banco, etc., mas preciso apenas para esse trecho (e pro embedding), que são onde de fato eu executo o modelo de IA o meu python. Então, somente ele precisa estar ali separado, o que me faz poupar uso desnecessáro das GPU do ZeroGPU, que é limitado.
Aqui, de novo, a biblioteca Sentence Transformers está tornando o meu uso de IA uma brincadeira de criança.
Muito obrigado ao time do Sentence Transformers, especialmente Tom Aarsen, que é core maintainer dessa biblioteca e sendo evoluindo ela muito!
A variável Rerank é uma instância do SentenceTransformers.CrossEncoder. Essa classe representam os modelos que fazem essa operação que expliquei acima, de comparar 2 textos e retornar um score. Eles são chamados de “Cross Encoders” devido a rede neural usada (que aceita 2 textos e gera um score) ao contrário do embeddings onde a rede usada é conhecida como Bi-Encoder, que processa separadamente cada texto, gera o embeddings que podem depois sere comparados.
Aqui é onde ela é definida:

Aqui novamente é um um modelo da mixedbread-ai, porém é um modelo específico para essa tarefa de rerank. Assim como o outro, você pode ver mais detalhes dele em: mixedbread-ai/mxbai-rerank-large-v1 · Hugging Face
A Classe CrossEncoder tem vários métodos que facilitam o uso… O método rank me permite passar um texto de consulta e a lista de documentos, então, o modelo vai retornar um score para cada string do segundo parâmetro. Aqui tem mais info sobre o rank: CrossEncoder — Sentence Transformers documentation
Um detalhe importante é que ela retorna valores negativos por padrao, é por isso que lá na criação do objeto, eu passei o parâmetro activation_fn, onde passo a função Sigmoide, que converte os valores para um range entre 0 e 1, o qual eu acho mais intuitivo para exibir no final.
Quanto maior o Score, mais relacionado os textos são. Então, eu preciso ordenar o resultado pelo Score. A função sorted do python faz isso pra mim:

No final desse processo, a variável RankedScritps terá o seguinte:
- Todos os scripts que foram encontrados semelhante ao texto do usuário
- Um score indicando o quanto esse texto é parecido, e está ordenado de forma decrescente por esse score
- O conteúdo de cada script e o caminho relativo dele no meu repo do GitHub.
- O cosine similarity apenas para fins de conferência
Agora, eu tenho dados reais que posso uar para apresentar ao usuário.
Até aqui, já seria suficiente exibi-lo em uma tabela, o próximo trecho faz exatamente isso: A função m() também retorna a variável CurrentTable, e como agora ela contém a nossa tabela, o yield faz ela ser atualizada. Nosso diagrama segue com uma pequena mudança, representando a tabela atualizada na interface pro usuário:

Nesse momento o usuário já consegue ver o que a query dele encontrou. Por exemplo, esse é o resultado quando eu pesquisei por “procurar uma string”:
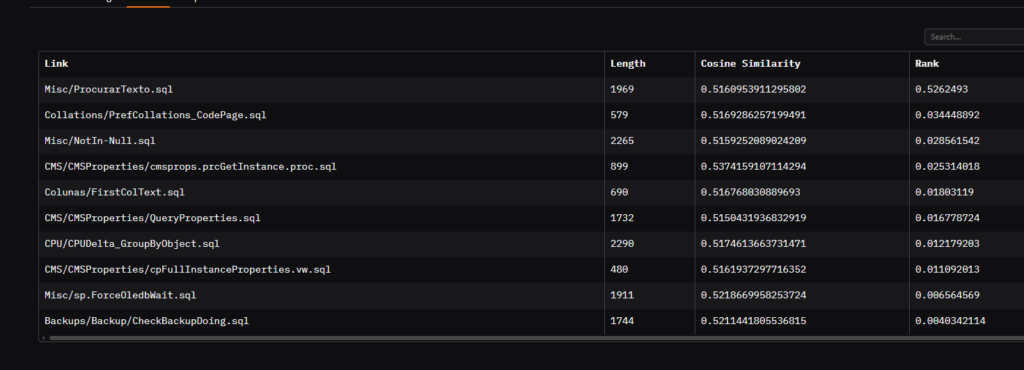
Esse resultado contém um exemplo muito legal de como o rerank foi importante. Repare a coluna “Cosine Similarity”. O primeiro script contém um valor 0.51, enquanto que o último contém o valor 0.52. Se eu não tivesse o rerank, um script que fala de backup teria vindo em primeiro, pois segundo a definição acima (lembra, cosine similarity = quanto maior próximo de 1, mais igual) ele seria mais parecido do que o script ProcurarTexto.sql
Agora, veja a coluna Rank. Note como o jogo mudou completamente. O score de ProcurarTexto.sql, é muito maior do que os demais, o que reforça o quanto o modelo acertou na relação entre o texto “procurar uma string” e o script. Por isso o rerank é extremamente importante aqui.
Ah Rodrigo, então porque você não usa sempre o rerank e tira o VECTOR_DISTANCE do meio? E a resposta é simples: performance. O Rerank é um processo muito eficaz, mas não escala bem para muitos dados. Eu precisei comparar apenas com 10 resultados, comparar com 100, é 10x mais trabalho. E, a tabela vai aumentar, pois eu tenho 400 scripts ainda para jogar lá (e crescendo). E, apesar de ser um número de linhas pequeno, o conteúdo pode ser muito: Lembre-se que o rerank atua em cima do texto para gerar o score, então, quanto mais texto, mais trabalho ele terá. Diferente do VECTOR_DISTANCE, que compara um array de números, e, portanto, é muito mais eficiente.
É por isso que no processo de RAG, é comum combinar essas duas operações: com embeddings, você acha um conjunto pequeno de candidatos relevantes, de forma eficiente, e com o rerank, aplicado nesse conjunto pequeno, você melhor classifica esse resultado. Diversas variações do RAG existem visando sempre adicionar operações para melhorar mais e mais a precisão desse resultado. O rerank é apenas uma delas.
Quinto uso de AI: Gerando uma resposta
Mas a brincadeira não para por aqui, pois ainda podemos usar o poder de um LLM para resumir e explicar o conteúdo desses scripts.
Agora que temos os dados, eu posso pedir um LLM que use essas informações para gerar uma resposta melhor elaborada ao usuário.
Após atualizar a tabela, eu peço a um LLM que gere uma mensagem de espera… O objetivo aqui é fornecer uma mensagem personalizada na tela para que o usuário saiba que ainda está sendo feito algo. Poderia ter deixado uma mensagem fixa ou usado um modelo menor, mas, de novo, optei pela praticidade:

Uma outra melhoria que eu poderia fazer é ter disparado essa mensagem em uma thread separada, no início dessa função. Assim, enquanto eu buscava os scripts e fazia o rerank, ele ja iria preparando essa mensagem. Pode ser que em versões futuras eu faça isso, pois aí eu não precisaria esperar muito só para gerar uma mensagem de wait…
E, finalmente, chegamos a parte em que eu peço ao LLM para elaborar uma resposta:

Aqui eu fiz um prompt usando um pouco de melhroes práticas (a famosa engenharia de prompt) para dar um contexto explicando do que se trata e como ele deve usar os resultados.
Eu passo diretamente, como JSON, a nossa tabela, para que ele use isso como contexto. Hoje em dia, os modelos já conseguem entender muito bem essa mistura. Eu também dou algumas orientações reforçando que ele deve analisar o script e o idioma em que deve responder.
Tudo isso vai no System Prompt, e como user message, eu passo o texto exato que o usuário digitou (não o texto traduzido). O System Prompt é uma instrução especial que os LLMs recebem e foram treinados para entender ela como um guia de como devem responder a mensagem do usuário.
Assim, eu deixo com o LLM toda a responsabilidade e criatividade para usar tudo isso e gerar uma resposta bem personalizada com base no que ele pediu e no que encontramos, inclusive dando a liberdade para que ele reordene os resultados se achar necessário. Uma vez que eu apresento a tabela com ordenada pelo Rerank para o usuário, então, eu não preciso garantir que a resposta siga essa ordem. Aqui é a pura criatividade da AI em ação e quanto melhor o modelo , melhor será a resposta.
Aqui caberia mais uma série de coisas interessantes. Por exemplo, se não tivesse resultado, ao invés de gerar esse prompt vazio, eu poderia apenas trocar o prompt dizendo que não houve resultados relevantes e fazer o LLM gerar uma resposta genérica. Mas eu optei por deixar como está para que ele sempre gere algo. Isso vai fazer com que os casos em que os scripts não são tão relevantes, gere alguma resposta forçada… Mas há muito espaços para melhorar isso.
O restante da função é apenas ele obtendo o resultado, a medida que chega e jogando no chat.

Próximos passos
Como voce notou, esse é um projeto bem simples e o meu intuito de faze-lo foi mais para estudar e aplicar muita coisa que eu estudei ao longo do ano de 2024.
Com certeza, temos muito espaço para melhorias do codigo, ferramentas que poderia usar, e até outras opcoes de bancos, como o Milvus.
Eu sou DBA SQL Server há mais de 10 anos, e no último me dediquei a estudar muito sobre Machine Learning e AI. E, estou realmente bem feliz em ver que o SQL vai vir com esse suporte forte a AI.
Acho que ainda veremos muitas novidades e como demonstrado aqui, acho que são features que tem tudo para serem amplamente usadas, principalmente essas que já usam pesquisas como FullText Search.
Algumas melhorias futuras que eu espero trazer:
- Quando o SQL Server 2025 for lançado, eu irei refazer a demo com ele, e com isso, poderemos testar com as funcionalidades que virão e que eu estou bem empolgado para ver!
- Há muito script pra adicionar ainda, então, as respostas tendem a ficar melhores
- Quero tentar usar um modelo de AI rodando diretamente no código, ao invés de chamar uma API externa,usando a GPU. Talvez possa até ser um SLM (Small Language Model).
- Sem querer, estou criando um dataset de T-SQL, graças aos comentários que estou fazendo na revisão do meu repositório git, então, eu espero um dia poder treinar um modelo de IA com estes dados e usar este modelo para gerar os resumos. Acredito que a respostas poderão ser bem melhores assim.
Acho que o principal insight desse post é mostrar o quanto de tecnologia já tem e o quanto isso está acessível para você conseguir criar solucoes com IA, que resolvem problemas de verdade do seu dia a dia.
Muito obrigado por ler até aqui espero que tenha gostado, e se você ficou com duvida em algum trecho de codigo, ou alguma explicação, é so deixar nos comentários que respondo assim que possivel!
Lembre-se que todo o código mostrado aqui é público e você pode conferir em:
- Repositório Git: rrg92/sqlserver-lib: Ferramentas e Scripts úteis para DBAs e Dev SQL
- PowershAI: rrg92/powershai: Powershell + AI
- Space Hugging Face: Sqlserver Lib Assistant – a Hugging Face Space by rrg92
Apaixonado por tecnologia e veterano em bancos de dados SQL Server, este entusiasta agora se aventura no fascinante universo da Inteligência Artificial.
Atualmente é o Head de Inovação da Power Tuning, onde é o responsável por trazer novas ideias para produtos e serviços, que melhorem a produtividade do time ou a experiência do cliente! Com muita experiência em programação, hardware, sistemas operacionais, e mais, agora quer juntar tudo isso nesse novo mundo e trazer muitas ideias e conhecimento sobre Inteligência Artificial!
Neste blog, vai compartilhar sua jornada de aprendizado e uso da IA, focando em como transformar nossa maneira de resolver problemas e inovar.