Canal Youtube
Canal YoutubeOlá pessoal! Seguindo a série sobre Inteligência Artificial no SQL Server 2025, enquanto eu não tenho acesso a uma instância para brincar e testar, eu vou assistindo os vídeos oficiais. E o mais recente que vi foi o da sessão do Ignite, onde Bob Ward, Joe Sack e Erin Stellato trouxeram muitas novidades com demos.
O vídeo está neste link, e aqui nesse post, vou falar apenas das minhas impressões sobre o que especificamente da parte de IA. Recomendo muito que você veja a sessão completa, pois há muitas novidades interessantes!
Um dos principais pontos que o Bob Ward reforçou é que o SQL Server 2025 é construído focado em 3 pilares, sendo um deles IA. E isso é um reflexo interessante, pois isso confirma algo que já comentava e já estávamos vendo em outros produtos Microsoft. Nest post eu fiz alguma previsões e o que saiu no sql server 2025 está um pouco longe da maioria dessas previsões ainda, mas uma em especial eu cheguei perto: pesquisa semântica.
Conforme mostrei no primeiro post dessa série, o SQL vem forte com a parte de vector search. E no vídeo, há uma diagrama mostrando muito bem aquela explicação resumida que deixei de como isso funcionaria:
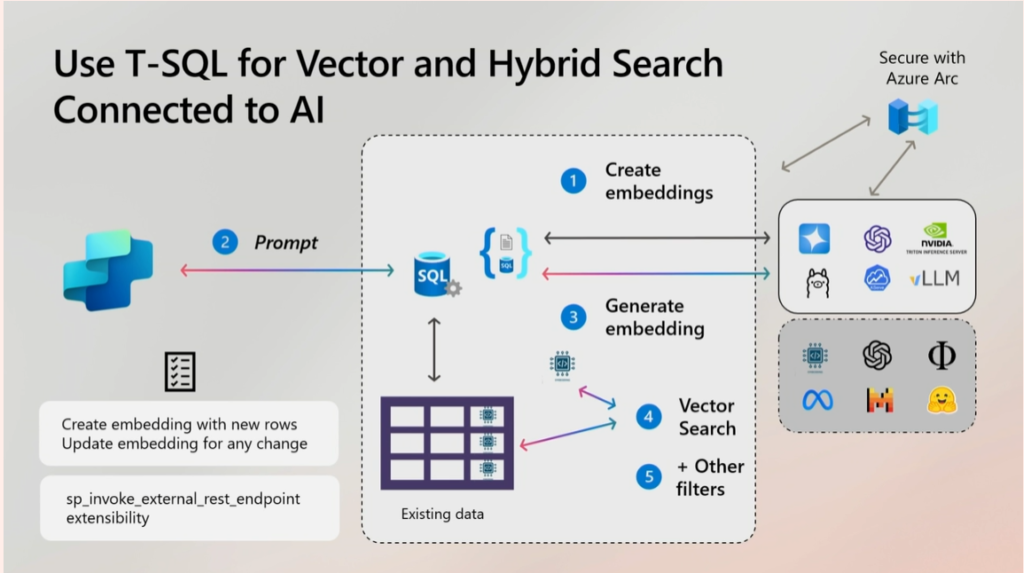
Aqui eu não vi surpresas, pois é um processo que já é esperado. Para quem está estudando IA , e coisas como RAG, sabe que é um processo bem trivial sem muita diferença, independente de onde está implementado. Então, aqui no SQL Server parece que seguiremos essa mesma linha padrão de indexação e pesquisa em vetores.
CREATE EXTERNAL MODEL
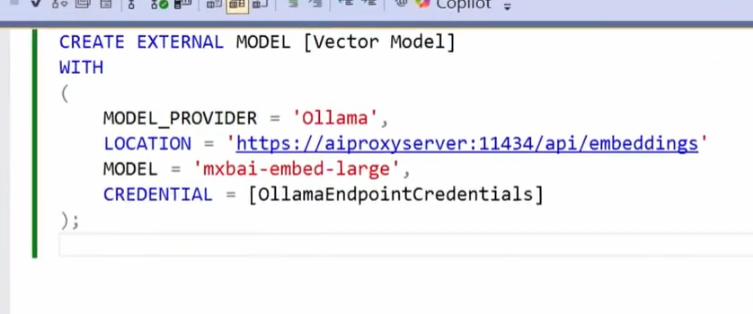
O grande destaque (e que me deixou muito empolgado) foi o primeiro comando que ele mostrou na demo:
No post anterior, chutei um CREATE AI MODEL… Quase… O comando será: CREATE EXTERNAL MODEL! Olhe só os parâmetros… E isso me pareceu tão familiar, pois os parâmetros lembram muito o que eu fiz com o módulo powershai (model, providers, etc.).
Bom, sem mesmo ver alguma documentação, ou funcionamento, vou tentar aqui acertar o que seriam esses parâmetros:
- MODEL_PROVIDER
Aqui você deve especificar um serviço que fornece API para modelos de IA. Existem vários deles por aí, pagos e open source. Ollama é um desses open source, que você pode subir em seu próprio computador. Provavelmente terão outros valores suportados, como OpenAI, Google, Hugging Face, etc. - LOCATION
Aqui provavelmente será a URL para acessar o serviço. Considerando que você pode subir modelos e expor em diferentes domínios, portas, faz sentido ter essa opção. Ainda sim, um mesmo provider pode ter URL diferentes dependendo do serviço. E o mais interessante: Já existem proxies, como o LiteLLM, que expõe uma API padrão (como OpenAI), e permite acesso a vários outros modelos. Ou seja, mesmo que o SQL Server não suporte diretamente algum provider, graças a esse parâmetro LOCATION e a serviços como o LiteLLM, você provavelmente conseguirá conectar o seu SQL Server com qualquer modelo de IA! - MODEL
Providers podem ter vários modelos. O modelo é o software que, de fato, gera o texto (ou os embeddings). É a IA, de fato, que produz algum resultado “mágico” pra você. Cada modelo pode ser diferente em relação ao custo, qualidade e desempenho, entre outros fatores. Por exemplo:- OpenAI, que é um provider, tem os modelos gpt-4o, gpt-4o-mini, etc.
- Google, que pode ser outro provider, tem os modelos Gemini Pro, Gemini Flash, etc.
- O ollama que é um provider que permite subir diveros modelos open source, te permite ter acesso a modelos como Llama 3.2 (da Meta), Phi-3 (Microsoft), Qwen (Alibaba), Aya (Cohere), etc.
- CREDENTIAL
E, obviamente, você vai precisar de credenciais, como Api Tokens, etc, para acessar esses serviços. E aqui, muito provavelmente o SQL irá reaproveitar um recurso antigo, que são as CREDENTIALS, criadas com o comando CREATE CREDENTIAL. Aqui é uma aposta minha, não vi nada confirmado, nem no vídeo, mas, diante de outras features e, de toda a segurança já existente, eu acredito que seja isso.
Uma coisa importante que você precisa ter em mente e, que é muito reforçado no vídeo, é que este comando não carrega nenhum modelo de IA dentro do SQL, muito menos no computador. É só um apontamento para uma API. Então, se alguém vir te falar que você vai precisar instalar um GPU ou comprar mais CPU para rodar esses comandos, desconfie se a justificativa for algo relacionado a rodar a IA dentro do SQL. Não, isso não é o que vai acontecer, pelo menos não nesta versão.
VECTOR DATA TYPE
Outra demo que teve foi a busca semântica usando o tipo vector. Eu estava empolgado para ver um vector index em ação, mas não foi dessa vez… Ele mostrou criando uma tabela com uma coluna do tipo vector, e especificando a quantidade de posições (vou esperar sair algo ou ter acesso a um SQL 2025 público para falar só disso):
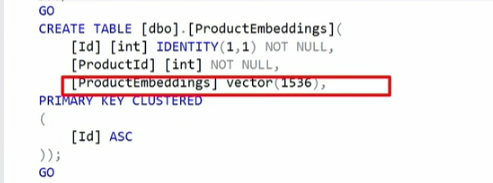
Então, ele demonstra como eles são:
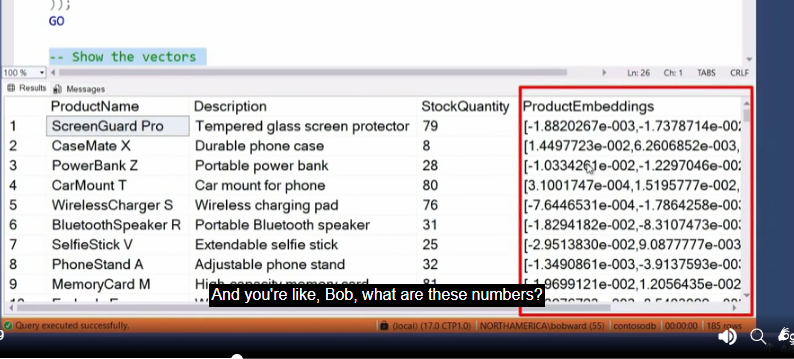
Segundo a doc oficial, eles são armazenados como um bináro de 4 bytes, para cada elemento. Se você tem um vector(100), então, cada linha dessa coluna ocupará pelo menos 400 bytes. Na visualização, eles são retornados pela engine como um array json. Ou seja, muito cuidado com esse tipo de dados e o tamanho da sua tabela…
A demo também mostrou um pequeno exemplo do uso da função VECTOR_DISTANCE, para fazer a busca por similaridade, nos modelos do que eu já tinha comentado: Você calcula o embedding do texto de busca, usando o mesmo modelo de IA, e compara usando essa função para obter os mais próximos.


Confesso que eu estava com uma expectativa mais alta para essa demo. Note que o código envolve usar a função VECTOR_DISTANCE para calcular o quanto o texto da pesquisa e o texto salvo na tabelas na tabela são distantes (quanto mais próximo de 1, mais distante). E, em seguida, ele usa uma expressão no filtro:
- 1 – distance
Isso transforma a distancia em similaridade. Se a distância é 0.1, então, 1 – 0.1, dá 0.9, o que significa “uma similaridade de 90%”. - Em seguida, ele filtra o resultado disso com o valor de um parâmetro, onde permite que a aplicação filtre apenas similaridades acima de um threhsold (é comum esse tipo de filtro, para evitar similaridades muito baixas).
- E por fim, ele mostra como você pode combinar isso facilmente com outros elementos do T-SQL já conhecidos, como JOINs e outros filtros.
Note que, a menos que exista alguma nova mágica no Query Optimizer em relação a estas expressões, muito provavelmente esse código irá produzir um table scan. E, vai por mim, você não vai querer pagar um table scan para achar produtos similares na sua funcionalidade acessadas por centenas de usuário por segundo…
Outra coisa que senti falta foi mostrar como ele gerou os embeddings. Não ficou claro se foi usando sp_invoke_external_rest_endpoint ou algum outro comando. O que ele mostrou, foi um procedure intermediária que ele mesmo escreveu:

E aqui, foi um outro ponto que eu fiquei um pouco frustado na demo. Eu esperava ver algum comando mais eficiente, uma função BUILT IN, talvez. Mas, se for apenas isso, então, atualizar os embeddings, será um processo procedural, isso é, você terá que, para cada linha, invocar uma proc e atualizar. Isso não é eficiente. Se for isso, talvez seja mais eficiente fazer usando alguma linguagem de script ou programação, que pegue os dados, chama o modelo, gere os embeddings, e atualiza de volta. Mas, vamos aguardar mais informações…
O resumo é que ainda senti falta de mostrarem um vector index, que, segundo as notas de lançamento, será algo que terá nativo (usando o algoritmo DiskANN). Mas não foi dessa vez. Pra mim, o vector index é o que vai tornar essa feature mais interessante, pois será graças a ela, que as buscas serão rápidas, e não fará com que você torre seu hardware (e dinheiro) fazendo scan naquela tabelinha grande, cheia de texto, que você deve tá doido para implementar o vector search…
Lembrando que o tipo vector já está disponível no Azure SQL Database, e você já poderia brincar aí gerando embeddings e inserindo no seu banco. Mas, ainda não vi nada sobre criar um vector index no SQL Database também.
Bom, pra resumir, esta sessão do Ignite trouxe, pra mim, algumas surpresas muito legais, e outras nem tanto. Mas, aqui eu to falando só da parte de IA… Há muitas outras coisas lá, que vou deixar para você assistir e tirar suas próprias conclusões. O apresentação está muito legal, bem intuitiva e cheia de animações que ajudam a entender as explicações! Se você trabalha com SQL Server, vale muito a pena conferir as novidades mostradas!
E eu sigo aqui, esperando uma oportunidade para testar tudo isso aqui na minha máquina (e já tenho case para testar em produção) e trazer várias dicas e insights pra vocês!
Apaixonado por tecnologia e veterano em bancos de dados SQL Server, este entusiasta agora se aventura no fascinante universo da Inteligência Artificial.
Atualmente é o Head de Inovação da Power Tuning, onde é o responsável por trazer novas ideias para produtos e serviços, que melhorem a produtividade do time ou a experiência do cliente! Com muita experiência em programação, hardware, sistemas operacionais, e mais, agora quer juntar tudo isso nesse novo mundo e trazer muitas ideias e conhecimento sobre Inteligência Artificial!
Neste blog, vai compartilhar sua jornada de aprendizado e uso da IA, focando em como transformar nossa maneira de resolver problemas e inovar.