Canal Youtube
Canal YoutubeQuando eu comecei a estudar sobre IA me deparei com uma enxurrada de novos conceitos: OpenAI, LLM, ChatGPT, parâmetros, modelo, llama, gpt, hugging face, modelo, rag, embedding, gguf, ahhhhh… É muito termo, é muita coisa 🤯🤯🤯🤯! Mas, eu já esperava, visto que é comum quando se encara um mundo novo de tecnologia.
Então, eu fiz o que fiz lá no passado com Windows e SQL Server: Fui procurando os conceitos básicos, aprendendo, testando, usando na prática… E isso está me ajudando bastante a entender melhor esse mundo!
Como é um aprendizado recente, eu resolvi materializar tudo isso aqui neste post (coisa que eu deveria ter feito com o sql no passado). Isso aqui vai me servir como um dicionário do mundo de IA. Eu vou atualizar ele sempre que eu ver um termo, ou conceito novo, principalmente esses que podem causar confusão. E, se você tiver algum aí que também tem dúvida, pode me sugerir.
É tanto conceito, tanta coisa, que resolvi fazer um “Mapa da IA”, mostrando a relação entre eles. Você pode clicar na maioria dos componentes que isso vai te levar pro tópico que o define:
Modelo de IA
Modelo é um dos termos mais comuns usados. A definição dele é bem ambígua… E acho que isso é o que causa mais confusão. O que me parece é que pegaram esse termo do Machine Learning e da matemática. As IAs são compostas de redes neurais. Uma rede neural é um modelo matemático. Então, acredito que esse termo foi fluindo lá da estatística até aqui no nível mais alto!
Eu aprendi que, IA não é só rede neural. As redes neurais são apenas uma parte. Então, toda vez que vejo o termo “modelo”, a primeira coisa que me vem na cabeça é um processo complexo, um sistema mesmo, que envolve várias etapas. Uma (ou mais) dessas etapas envolve jogar o dado em uma rede neural, e tratá-lo de volta. Enxergar um “modelo de IA”, como esse sistema todo, ficou mais fácil de entender pra mim.
Mas, de fato, o termo pode ser bem ambíguo, então o contexto é importante. Com os demais termos que veremos nesse post, você vai entender em outros significados o termo “modelo” também é usado.
A dica aqui é: pense num modelo como um sistema, que possui código e redes neurais, recebem dados que fornecemos pra eles e retornam algo:
- Temos os LLM (Large Language Models), que são modelos pra gerar texto
- modelos que geram imagens
- modelos que transformam imagem em texto
- modelos que transformam voz em texto
- modelos que transformam texto em voz
- modelos que geram música
- modelos que podem fazer previsão climáticas
- modelos que podem fazer análise preditiva
- modelos que conseguem descrever uma imagem
- modelos que separam instrumentos de uma música
- (e muito mais)
A menos que você seja um programador python, C++, etc., dificilmente você interage com esses modelos diretamente, e na maioria dos casos, você usa algum aplicativo ou site, e este site é quem pega os dados que você fornece (texto, imagens) e envia pra alguma API. É essa API é quem comunica diretamente com o modelo (ou quase ela). O fato é que é muito improvável que você acesse o executável do modelo diretamente. Isso geralmente é só em fase de dev mesmo.
No final desta página há um pequena definição que possa deixar mais claro essa definição de modelo.
OpenAI
A OpenAI é uma empresa de tecnologia, privada, que desenvolve modelos de IA, e o mai famoso é o nome que você provavelmente já conhece: GPT. Mas além do GPT, eles possuem outros, como o Whisper (transcreve áudios), o DALL-E (gera imagens) e o Sora (gera vídeos).
GPT é a sigla para Generative Pre-Training. E, na verdade, não é um modelo (aqui usamos o termo de forma ambígua, igual o resto do mundo). É uma arquitetura criada pela OpenAI que define um LLM: São modelos que geram texto de forma natural! Um exemplo de um modelo que você já deve ter ouvido falar é o GPT-4 (além de modelo, gpt-4 também é a arquitetura, isto é, eles desenvolveram a arquitetura GPT-4 e criaram um modelo em cima dessa arquitetura, com o mesmo nome).
Basicamente, os caras foram responsáveis por furar a bolha da IA e fazer até minha avó falar de inteligência artificial. Fizeram isso colocando estes modelos por trás de um produto bem famoso: o ChatGPT. O ChatGPT é um site, onde você tem um interface de um chat, em que pode enviar mensagens. E, ao invés de conversar com outra pessoa, você está conversando com um destes modelos. O ChatGPT tem uma versão paga e uma versão grátis. A versão grátis é limitada em, por exemplo, quantidade de mensagens que você pode enviar por dia ou por hora. Se você pagar a assinatura (igual eu pago), você pode conversar com limites muito maiores e tem acesso a um monte de outras funcionalidades. Não é raro você encontrar por aí alguém falando que foi o ChatGPT (principalmente o gratuito) que fez a IA se popularizada no mundo inteiro. E eu acredito fortemente nisso.
Além de um chat em que qualquer pessoa pode usar e ver por si só os poderes de uma IA, qualquer empresa, ou desenvolvedor, pode trazer essa funcionalidade para o seus apps, sites, etc.: A OpenAI tem uma API, onde você coloca créditos e estes créditos são consumidos conforme o uso. O consumo é baseado na quantidade de tokens que você envia e recebe. O texto que você envia (ou recebe) é quebrado em tokens, que são números representando partes do texto. Estes modelos produzem tokens, e por isso, é a unidade de cobrança na API da OpenAI.
Eu escrevi um post falando só sobre eles. Vale a pena conferir se quiser mais detalhes de como a OpenAI funciona.
LLM
LLM (Large Language Models) são modelos de IA treinados com grandes quantidades de texto. A principal funcionalidade destes modelos é entender e processar linguagem natural, como receber um texto de entrada e completá-lo, respondê-lo, resumir, etc. Basicamente, essas IAs geram texto. O “Language” no nome vem desse fato de ser voltado ao processamento de linguagem.
Uma outra característica é que essas IAs possuem uma grande quantidade de do que chamamos de parâmetros (ou pesos). É daí um dos motivos da palavra “Large”. É comum você ver alguma notícia que uma empresa lançou um novo modelo com X BILHÕES de parâmetros. Exercício simples para você imaginar a magnitude disso: Sem usar uma calculadora, faça essa conta: 2x+10+x²-1.31log(50), com x = 10, depois com x = 3,11. Difícil? Pois é, agora imagine 1 bilhão de operações dessas, com diferentes números… Não, não, não vamos muito longe assim, imagina, apenas mais mil operações de soma ai no meio… Entendeu a magnitude de um LLM? Cada vez que você conversa com o ChatGPT, por exemplo, ele está fazendo isso… várias vezes…
Junto com LLM, novos conceitos se tornaram bem comuns: tokens e embeddings. Tokens é o que as redes neurais desses modelos processam e produzem. Antes de jogar o texto na rede, eles são convertidos pra token (entrada), ou convertidos de tokens pra texto (saída). Embeddings é um jeito que eles usam para entender mais sobre a semântica do texto, isto é, o significado e conexto. Tem um tópico para um destes dois termos nesse post.
E, um outro nome, se tornou comum, são os SLM (Small Language Models), que são modelos de IA que também geram texto, mas são menores do que um LLM. Geralmente, um SLM é um versão de um LLM, com bem menos parâmetros, e que pode rodar em ambientes com menos recursos.
Atualmente, já existem vários LLMs (e SLMs), desde comerciais aos open source. Alguns exemplos:
- OpenAI GPT-4 (comercial, LLM)
- Meta Llama 3 70B (LLM, open source) (o 70B é de 70 bilhões de parâmetros)
- Meta Llama 3.2 1B (SLM, open source) (1 bilhão de parâmetros)
- Google Gemini Flash (comercial)
- Google Gemma (SLM, open source)
- Microsoft Phi-3 (SLM, open source)
- SABIA-3 (comercial, LLM brasileiro, da empresa Maritaca.AI)
A grande maioria desses modelos são baseados na arquitetura Transformers, que foi introduzida pelo paper Attention is All You Need (que ainda não li, mas ainda vou ler com calma). Mais adiante falo também do conceito de arquitetura para entender a diferença entre “modelo”, “llm” e arquitetura.
Redes Neurais
A Rede Neural é a parte da IA que aprende. É difícil imaginar como uma “calculadora” aprende (sim, tomei a liberdade de chamar um computador de calculadora aqui)… Mas o segredo que me fez entender o que é uma rede neural é a matemática. Eu aprendi que uma rede neural, na verdade, é uma função matemática. Só que ao invés de escrever f(x) = Ax + b, representamos de uma outra maneira, para que seja algo mais modular e talvez mais fácil de transformar isso em código.
Dentro do assunto de redes neurais, você tem uma porrada de conceito matemático combinado: Regressão linear, derivadas, estatísticas, etc. Montar uma rede neural que é capaz de aprender, ser reutilizada em uma arquitetura, produzir algo, etc., é uma arte e por isso que tem áreas, pesquisa, formação e profissões e formação só pra isso… Este cara que vos falar é um simples entusiasta… Tem que respeitar os PhD (os de verdade, não os que compraram diploma) que são verdadeiros cientistas descobrindo coisas de redes neurais que no futuro serão a base de vários modelos de IA…
Os modelos de IA podem conter uma ou mais redes neurais. Podem conter redes neurais genéricas, criadas para resolver problemas específicos, combinados com outras redes, etc. É isso que torna a IA dinâmica e “inteligente”. Há um documentário na netflix (o Corpo Humano), e há um trecho que faz entender isso muito facilmente (veja o episódio “Pulsação”, minuto 35:15): Há vários mini sistemas nervosos espalhados no seu corpo… no coração, no intestino, olhos… E, para mim, isso ilustra muito bem o que é uma IA: Um sistema com várias redes neurais, desempenhando papéis distintos, tarefas específicas, e que torna o todo, mais dinâmico e inteligente.
O artigo que me fez clarear sobre redes neurais foi esse do Jay Alamar. Foi tão bom, que eu traduzi uma primeira parte aqui no blog.
E, além desse artigo, outros assuntos me ajudaram como base para entender os demais conceitos. Alguns vídeos que eu assisti depois de ler o artigo:
Introdução a Redes Neurais e Deep Learning (youtube.com)
A matemática do Gradiente Descendente & Regressão Linear (machine learning) (youtube.com)
O Melhor Exemplo Prático de Machine Learning / Redes Neurais para Iniciantes – TensorFlow (youtube.com)
qual a equação da reta tangente à curva f(x) = 2x²-4x+4 no ponto x = 2 ? Somatize – Professora Edna (youtube.com)
A maioria desses vídeos são bem baixo nível, mas me ajudaram a entender, principalmente, a parte conceitual do treinamento, e os porquês de algumas coisas. É muita matemática mesmo… Mas com um pouco de paciência e as fontes certas, as coisas vão fazendo sentido. Se você quer saber como uma rede neural funciona de uma maneira mais leve, sem precisar calcular uma derivada, dê uma chance para o post que traduzi acima… Quem sabe depois dele, você já não via conseguir ler os artigos dos Phd com muito mais tranquilidade…
Como redes neurais são apenas matemática, você pode implementá-las usando qualquer linguagem de programação. Porém, implementar redes neurais do zero, pode ser bem complexo. Existem várias bibliotecas que facilitam e muito a criação de redes neurais. Exemplos: Pytorch (criado pela Meta) e TensorFlow (criado pelo Google). Essas bibliotecas geralmente cuidam de implementar detalhes, como o uso de GPU, deixando o desenvolvedor com o foco na construção da rede em si e na solução do problema que essa rede vai resolver!
O que não seria do mundo da programação sem essas bibliotecas e frameworks, hein!?
Arquitetura
Nesse contexto de IA, a arquitetura é a “estrutura” de uma IA. As IAs possuem uma arquitetura que pode ser implementada em qualquer linguagem. Ela é algo em um nível mais conceitual. Por exemplo, você pode desenvolver uma IA que é composta por 3 redes neurais, onde a primeira tem 20 parâmetros, e deve receber texto representado por números de 4 bytes.
Acho que posso dizer (e os Phd me perdoem) que a Arquitetura de um modelo é como se fosse um algoritmo bem gigante, com várias etapas, sendo algumas dessas etapas usando redes neurais, mas não se limitando a elas… Além das redes neurais, define as operações envolvidas desde os dados que recebe até os dados que produz.
Eu gosto de imaginar a arquitetura como se fosse uma arquitetura de processador. Existem vários modelos de processador, como o x86, x64, arm… Cada possui características únicas, operações, disposição dos elementos, operações que pode realizar, etc., desempenho, etc. Assim é como as arquiteturas de IA.
E, por mais que sejam diferentes arquiteturas, elas tem algo em comum: os parâmetros das redes neurais. Sem eles, sua IA é um zumbi. Não faz nada, ou, se fizer, fará algo completamente errado. Os parâmetros são os valores encontrados no treinamento, que fazem as redes neurais envolvidas produzirem os valores esperados em cada etapa! E, como uma arquitetura pode conter várias e várias redes neurais, ela pode facilmente conter milhares, milhões ou bilhões de parâmetros!
É muito comum se referir à arquitetura pelo termo “modelo”. Geralmente eles são usados como sinônimo. Exemplos de nomes que são, na verdade, arquiteturas, mas chamamos de modelo normalmente: GPT-4, GPT-4o, GPT-3.5, Gemini, Gemma, Llama, Mistral
Uma vez que as arquiteturas são “definições”, elas podem ser implementadas em qualquer linguagem. Mas, na grande maioria dos casos, pela facilidade, elas são implementadas usando PytTorch ou Tensorflow.
Por exemplo, no python, temos a biblioteca python Transformers, criada pelo Hugging Face, que implementa a arquitetura de mesmo nome. A arquitetura Transformers é usada por muitos modelos de IA, incluindo LLM. Temos o llama.cpp, que também implementa diversas arquiteturas em C++ puro, sem dependências.
Uma vez que você tem a arquitetura implementada, rodar um modelo é basicamente carregar o arquivo que contém os parâmetros desse modelo: a arquitetura com suas redes neurais está lá, pronta para ser preenchida com os valores dos parâmetros. Isso é o que permite, com o mesmo código, rodar diferentes modelos baseados na mesma arquitetura.
Sempre que eu vejo o termo “arquitetura”, eu imagino um processador cheio de circuitos e complexo… Mas que só vai fazer algo quando um programa for carregado nele (e o programa nesse caso, são os parâmetros/pesos)
Fontes:How do Transformers work? (huggingface.co)
Parâmetros (Pesos)
Arquiteturas podem ser compostas por uma ou mais redes neurais. Cada rede neural pode ter parâmetros. Muitos parâmetros. Esses valores numéricos que são usados nas operações matemáticas das redes neurais. Treinar uma IA é o processo pelo qual descobrimos o melhor valor desses parâmetros.
Lembra da definição de redes neurais, que são funções matemáticas? Por exemplo, imagina uma função nesse formato: y = 2x + 1. Neste exemplo, temos dois parâmetros: 2 e 1. Os parâmetros são estes valores constantes da função. Em uma rede neural, eles são descobertos no processo de treinamento. Neste caso, o valor 2 e 1 não necessariamente são os melhores valores. Depende do resultado de y que queremos para cada X. Essa relação entre a entrada X e saída Y fica no que chamamos de “Dataset”.
Estes valores também são chamados de pesos (e bias), porque geralmente eles são multiplicados ou somados aos valores para interferir no resultado. É muito comum você ver o termo pesos (em inglês, weights). Está se referindo aos parâmetros.
Note que você não deve confundir as entradas da rede neural (ou do modelo) com os parâmetros/pesos. As entradas são informações externas que são fornecidas. São valores dinâmicos, que a IA vai ter que processar e produzir um resultado. Os pesos são valores fixos. Uma vez que o modelo foi treinado, eles ficam fixo no processamento. Na função acima, a entrada é o X (e poderia ter X1, X2, X3, etc.). Os parâmetros são os valores constantes.
Ter mais ou menos parâmetros não significa ter mais ou menor qualidade. A qualidade depende também de outros fatores, como a arquitetura em si, qualidade dos dados de treino, etc. Porém, a quantidade de parâmetros impacta diretamente no consumo de recursos exigidos pelo modelo. Mais parâmetros pode significar mais memória e processamento. Existem técnicas que ajudam a “comprimir” esses parâmetros, como, por exemplo, uma técnica chamada quantização.
O processo de treinamento serve justamente para descobrir esses valores. É um processo que pode levar de segundos a dias. Os modelos são inicializados com valores nos parâmetros (existem várias técnicas para essa inicialização, podendo ser, por exemplo, valores aleatórios). Ele fica repetindo várias vezes, inserindo os dados de entrada do dataset, checando a saída, comparando com o que é esperado e usando funções matemáticas para alterar o valor. Se descobrir os 2 pesos para uma rede neural como 1 entrada pode consumir alguns recursos significativos da sua CPU, imagina descobrir bilhões de parâmetros para uma rede com, por exemplo, 8000 variáveis de entrada. É por isso que usar GPU é muito valioso.
As bibliotecas como o PyTorch e o Tensorflow conseguem exportar arquivos com os valores desses parâmetros. Cada conjunto de parâmetros que foi salvo é chamado de Checkpoint. Estes valores de parâmetros podem ser salvos em diversos formatos de arquivos. Por exemplo, a biblioteca PyTorch pode salvar em arquivo com a extensão .safetensors e tensorflow como .h5. Isso é o que permite compartilhar modelos, o resultado de um treinamento e/ou continuar de onde parou.
Compartilhar os detalhes da arquitetura de um modelo sem os pesos que foram encontrados no treinamento é uma prática comum. Quando se compartilha os pesos, podemos dizer que o modelo é Open Weight. Sem os pesos, você deve construir um dataset e realizar o treinamento manualmente. E isso ainda não garante que os mesmos pesos serão obtidos! Empresas podem optar por não compartilhar os pesos por estratégia comercial.
Esse post traz um exemplo mais prático para aprender como as redes neurais funcionam e os seus parâmetros são descobertos
Datasets
Um Dataset é um arquivo que contém dados para treinar um modelo de IA;
Geralmente, ele é parecido com o arquivo CSV, JSON, etc. O formato exato depende da arquitetura do modelo onde você vai usá-lo.
O dataset contém a relação entre as entradas do seu modelo e as saídas (o valor dos X de entrada e o Y de saída esperado). E com isso, você consegue treinar o seu modelo para encontrar os parâmetros que fazem o modelo chegar o mais perto possível desse resultado.
A qualidade do dataset interfere diretamente na qualidade do modelo. Ter um dataset de qualidade é um dos maiores desafios no mundo da IA.
Tem dataset de todo tipo:
– Dataset com imagem e a descrição da imagem, para treinar modelos que aprendem a ler imagens
– Dataset com questões e respostas, para treinar modelos que respondam os mais variados assuntos
– Dataset com assunto e um rótulo (label), para treinar modelos que classificam um texto, imagens, etc.
– Dataset que áudios e a descrição do áudio, para treinar modelos que fazem transcrição
– Dataset com código e a descrição, para treinar modelos que geram código
Esse post não fala sobre datasets, mas você pode ter uma noção de como amostrar reais podem ajudar a treinar a IA. No caso do post, o dataset seria é a relação entre o preço e a área coletado com os amigos.
Checkpoint
Os checkpoints são os arquivos (que podem ser binários) com os valores dos parâmetros (pesos e bias) que foram descobertos durante um treinamento. Dependendo da biblioteca usada eles podem conter extensões diferentes. No PytTorch, por exemplo, a extensão é .pt. No tensorflow, é .ckpt.
Além dos checkpoints, os pesos também podem ser compartilhados em outros formatos de arquivos. Cada formato de arquivo depende da biblioteca usada e o propósito. Esses formatos podem incluir informações adicionais, como a estrutura do modelo e outros metadados.
Os checkpoints são mais focados para salvar o progresso do treinamento, enquanto que as outras extensões salvam os parâmetros para um modelo final, já treinado, pronto para ser compartilhado. De todo jeito, não é incomum ver os checkpoints serem compartilhados e carregados para testar o resultado de uma IA.
Inferência
Inferência é um termo bonito para “executar o modelo”. Basicamente, quando queremos que um modelo (ou uma rede neural) faça o seu trabalho e gere um resultado, chamamos essa ação de “Inferência”.
A inferência está mais relacionada a rede neural em si. Então, geralmente, a gente fala “inferir o modelo”, mas, como o modelo pode conter uma arquitetura com muitas coisas além da rede neural, o termo não estaria preciso… Mas, é usado normalmente e tudo bem.
Sempre que você ver em algum lugar dizendo que “vai inferir um modelo”, imagina apenas como “vou enviar algum dado pro modelo retornar um resultado”. Obviamente, o conceito é um pouco mais amplo que esse, mas pensar assim facilita demais o dia a dia.
Tokens
Token é o formato de entrada aceito pela maioria dos LLM. LLMs não entendem texto. Eles entendem números (Afinal, uma rede neural é uma função matemática, e, naturalmente, é capaz de processar apenas números).
Logo, para ser capaz de processar texto, ele precisam fazer um pré-processamento de texto, que é convertê-lo em números. Esse é o processo chamado de tokenização, que é feito por componente chamado tokenizer.
Cada arquitetura define qual formato de token suporta. Pode ser um tokenizer novo, definido com a própria arquitetura, ou pode ser um tokenizer padrão, usado por vários modelos.
O fato é que, LLM vão receber tokens e produzir tokens. Isto é, é preciso um tokenizer antes e depois da inferência. O tokenizer pode ser simples como quebrar palavras pelo espaço, ou complexo a ponto de considerar elementos exclusivos da sintaxe e gramática da linguagem.
Tokenizers são um exemplo simples de que um modelo de IA não é composto apenas por redes neurais. Este é um componente que é crucial para que o modelo produza os resultados, mas não é uma rede neural em si.
Quantização
Quantização é o processo de reduzir o tamanho de um modelo.
A maior parte do tamanho do modelo de IA vem dos parâmetros. Os parâmetros são valores numéricos e geralmente possuem um tipo de dados que consomem bastante bytes. Geralmente é um float de 32 bits (4 bytes).
Isso significa que, por exemplo, um modelo com 10 bilhões de parâmetros, consome, pelo menos:
10.000.000.000 * 4 bytes = 40GB.
40GB só pra sorrir, ou, em outras palavras, só pra carregar o modelo em memória.
Os valores desses parâmetros nem sempre precisam de um tipo de dado tão grande assim. Muitos valores podem ser otimizados, reduzidos para caber em poucos bytes (e até em poucos bits), como inteiros de 8 bits (1 byte), por exemplo.
E é exatamente isso que o processo de quantização faz. O objetivo desse processo é reduzir esse tamanho sem alterar o resultado do modelo significativamente. Afinal, uma vez que você mexe nos pesos, você está diretamente interferindo no resultado do modelo. Se onde o valor era, por exemplo, 3.141516, você trocar por 1.1, isso pode mudar tudo! Então o processo de quantização tem que ter esse cuidado.
Graças a esse processo, muitos modelos podem rodar localmente cada vez mais rápidos e usando menos recursos.
Se você quiser saber mais detalhes desse processo, eu recomendo MUITO e leitura desse guia visual sobre quantização: A Visual Guide to Quantization – by Maarten Grootendorst
🤗 Hugging Face
Hugging Face é um site que oferece diversos serviços relacionados a IA, principalmente voltado para a comunidade Open Source. Isto é, há muitos recursos que você pode usar, gratuitamente. Ele tem essa cara do emoji 🤗 (que curiosamente não se chama “hugging face”, e sim smiling face with open hands)
Lá você encontra diversos modelos de IA, incluindo muitos com os pesos publicados. Você também encontra datasets e tem uma seção reservada apenas para demonstrações de uso desses modelos. Tudo isso é alimentado pela própria comunidade mundial de desenvolvedores e empresas (gigantes como Google, Microsoft e OpenAI publicam lá). É o “GitHub” da IA. Há também diversos cursos, tutoriais, blogs, todos gratuitos, criados por experts da área, sobre os mais variados temas. Eles chamam esse site de Hugging Face Hub.
Além do Hub, o Hugging Face também é o criador da biblioteca Transformers. Essa é uma biblioteca python que implementa a arquitetura Transformers.
Essa arquitetura é a base para a maioria dos LLMs atuais e outros modelos. A biblioteca python, chamada Transformers (que tem o mesmo nome da arquitetura) abstrai uma série de detalhes de implementação, permitindo rodar modelos de uma maneira muito mais simples, e com poucas linhas de código. E, a biblioteca é completamente integrada ao Hugging Face Hub. Você pode facilmente baixar os modelos compartilhados e colocar para rodar. E, da mesma forma, treinar estes modelos é muito mais simples. Por debaixo dos panos, essa biblioteca usa as outras já mencionadas: PyTorch ou Tensorflow. Isso significa que ela pode exportar os modelos no mesmo formato suportado por essas bibliotecas, o que facilita ainda mais o compartilhamento e reuso.
Em suma, é no Hugging Face onde você vai encontrar diversos modelos de IA, os mais variados, criados por gente de todo o mundo.
Este postcontém mais informações sobre o hugging face e demonstração em vídeo.
Fontes:
Hugging Face Hub documentation
Introduction – Hugging Face NLP Course
Gradio
O Gradio é uma biblioteca python para criar demonstrações.
De um lado temos várias bibliotecas para criar redes neurais, rodar modelos, etc. Porém, para ter acesso aos resultados desses modelos de IA, você precisaria saber programar!
É aí que entra o Gradio. Ele é um framework voltado exclusivamente para o mundo de IA. Um desenvolvedor pode criar um programa python, que usa o Gradio, para facilmente criar uma interface web que permite você interagir com os modelos. Assim, fica muito mais fácil compartilhar exemplos de como um modelo de IA funciona e até mesmo criar um site bem complexo, com diversas funcionalidades, que usam IA (apesar do Gradio ser voltado para demonstrações, há muitos projetos que o utilizam como parte final da interface).
O Gradio foi adquirido pelo Hugging Face e as últimas versões são completamente integradas. Inclusive, no próprio Hugging Face, você pode hospedar aplicações usando Gradio. Isso faz do Hugging face ainda mais dinâmico, permitindo, no mesmo lugar, que você tenha o modelo de IA, o dataset e um local para testá-los.
Inference Engine
É um software que cuida de carregar modelos, provê uma API para acessá-los e fazer inferência. Dado que as arquiteturas podem ser implementadas separadamente dos modelos, existem vários softwares criados, que implementam diversas arquiteturas, e permitem que você carregue os modelos, e possa expô-los através de alguma REST API, linha de comando, gerencie a memória usada, usuários, etc.
Atualmente, já existem várias opções:
– ollama (que, na verdade, usa o llama.cpp)
– vLLM
– Hugging Face TGI
– LMDeploy
(dentre outras)
Essas engines facilitam e muito o carregamento de diferentes modelos, permitindo que você tenha acesso a diversos modelos e usando um jeito padrão para acessá-los, fazer inferência e obter o resultado. E, não apenas o carregamento, mas cuidam de outros aspectos cruciais para garantir que eles rodem bem: Gerenciam a memória, GPU, CPU, expõe API REST para acessar o modelo, etc.
Nós não precisamos de uma inference engine para rodar um modelo. Mas, ela são extremamente úteis quando queremos ter um jeito de publicar estes modelos como serviço, ou se queremos publicar vários modelos juntos… Graças a essas engines, esse trabalho fica muito mais fácil.
É muito mais fácil começar por uma engine dessas do que você programar uma biblioteca do zero, que vai carregar o modelo, você vai ter que se preocupar com checar hardware, etc.
GGUF
GGUF é um formato de arquivo usado pela biblioteca llama.cpp, (e, consequentemente, pelo ollama) que contém os valores dos parâmetros de um modelo. Ele é mais um formato de compartilhar os pesos dos modelos. E, inclusive, suporta quantização.
O fluxo comum é que um desenvolvedor crie e treine seus modelos de IA, usando PyTorch, TensorFlow ou a própria biblioteca Transformers, e então publique no Hugging Face. Posteriormente, esse mesmo desenvolvedor, ou outros, podem pegar estes arquivos publicados e convertê-los para o formato GGUF, que então pode ser carregado no llama.cpp (ou no ollama, ou em qualquer outra engine que suporte GGUF).
Existem várias ferramentas para fazer essa conversão. Exemplo: GGUF My Repo – a Hugging Face Space by ggml-org
Fontes:
ggml/docs/gguf.md at master · ggerganov/ggml (github.com)
ONNX
ONNX é outro formato de arquivo para compartilhar os pesos do modelo (e outras informações), e que também suporta quantização.
Para rodar esses formatos, você precisa do onnx runtime, que é disponível em várias linguagens, como python e .NET.
Inclusive, a biblioteca Transformers.js (versão em javascript da Transformers) aceita somente os formatos ONNX. Então, se você quiser carregar um modelo diretamente no browser usando Transformers, deverá usar a versão ONNX dele (ou converte um existente para ONNX)
Embeddings
Os embeddings representam características de uma palavra, frase ou texto, de uma forma numérica.
Existem modelos de IA treinados para identificar essas características. Eles recebem um texto e retornam um valor numérico que representa essas características. Na verdade, esse valor numérico é um array de valores decimais (geralmente o tipo float).
De forma bem resumida: Cada elemento desse array representa alguma característica e o valor indica o “quanto” dessa característica.
Mas a grande sacada do embeddings é que, além de conseguir representar a semântica de um texto, ele é comparável. Isto é, se você tem 2 textos que possuem significados parecidos, o embeddings desses textos vão ser muitos parecidos. Existem cálculos matemáticos como Similaridade por Cosseno (Cosine Similiarity) que podem ser usados para calcular % de quanto são parecidos.
Mas não para por aqui. Imagina que você tenha um banco de dados com vários textos (por exemplo, descrições de produtos) e precise procurar os produtos que sejam o mais próximo de uma descrição. Uma das maneiras de fazer isso é por pesquisa de texto e sinônimos, mas isso requer que o seu texto de busca e os do banco de dados tenham termos em comum. Ou: calcular o embedding de cada texto e armazenar em uma coluna a parte no banco (faria isso 1x, ao armazenar o texto). Então, ao fazer a pesquisa, você calcula o embedding do texto da pesquisa, e compararia ele com o embedding de cada descrição salva no banco. Retornando apenas os mais próximos ( por ex.: acima de 80% de similaridade)
Esta abordagem funcionaria bem para poucas linhas, mas para uma gama maior de dados, varrer tudo seria bem ineficiente (galera que é de banco de dados sabe o quão ruim um scan pode ser). É aí onde entram os Vector Databases e os diversos algoritmos de indexação de embeddings. Sim, já existem diversos bancos de dados em que você consegue indexar embeddings e procurá-los de uma maneira muito eficiente, sem precisar varrer tudo.
Cada algoritmo tem vantagens e desvantagens. Por exemplo, existem algoritmos que são muitos rápidos, porém são menos precisos do que varrer tudo (eventualmente, um pequeno conjunto de descrições não seria retornado buscando pelo índice, mas seria retornado buscando pelo scan completo). Dependendo do caso, é aceitável perder um pouco de precisão e ganhar muito em velocidade.
Embeddings são uma das peças fundamentais de modelos que envolvem processamento de texto, E n
ao só texto, mas imagens, áudio, etc. É possível calcular os embeddings de diversas informações que, para nós humanos, conseguimos atribuir significado facilmente, mas que é muito mais difícil para a máquina.
Se vc quer saber mais detalhes dos embeddings, maus uma vez o Jay Alammar explica muito bem aqui:
The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)
RAG
Retrieval-Augmented Generation (RAG), é um processo para fazer o LLM responder melhor, com dados contextuais, e não somente com dados de treinamento. Eu vejo muitas traduções para esse nome, mas acho que a melhor seria: Geração (de texto) baseada na pesquisa ou Geração embasada por dados externos. Eu acho que a tradução literal (Geração aumentada de recuperação) mais atrapalha do que ajuda.
Quando você pergunta algo a um LLM, ele pode começar a responder loucuras se no dataset de treino tinha muito pouca informação sobre aquele assunto. Para compensar isso, se você der um resumo, ou contexto sobre o assunto, o LLM pode responder muito melhor.
E é ai que entra o RAG. Se você tiver um banco de dados com algo sobre aquele assunto, você poderia calcular embeddings do texto que está enviando ao LLM, obter um TOP X textos que mais tem relação com o assunto, e jogar isso no contexto do LLM. Então, o LLM poderia considerar isso ao gerar a resposta.
Note que isso é uma descrição bem simplificada. Há várias técnicas dentro do processo de RAG e várias vertentes (GraphRAG, WalkingRAG, Fusion RAG, Re-rank, etc.)… Tem muitas coisas e estão sendo descobertas muitas coisas ainda… Mas é um processo super interessante e tende a produzir resultados incríveis e com muito menos esforço do que seria treinar um LLM para os seus dados.
Groq
Groq é uma empresa que oferece serviços de LLM na nuvem, expondo uma API para que você possa conversar com diversos LLM open source. Eles criaram uma tecnologia chamada LPU, que é dispositivo, assim como a GPU, voltado para otimizar a execução desses LLM…
Maritaca AI
Maritaca AI é uma empresa brasileira que criou e treinou um LLM chamado SABIA. E, muito provavelmente, são os primeiros brasileiros a treinarem um LLM e disponibilizar comercialmente em API. O modelo deles possui a mesma arquitetura do Llama (e pode conter algo a mais, uma vez que não temos muitos detalhes da última versão lançada). De qualquer forma, eu acho muito bacana essa iniciativa de ter um modelo treinado por BR… Isso demonstra o quanto nós BR temos potencial. Saiba mais sobre eles em Maritaca AI | Modelos de linguagem
Eleven Labs
A Eleven Labs é outra empresa que fornece serviços de AI, e um dos fortes são os que convertem texto para voz, ou, no termo comum, TTS (Text to Speech). No site, eles se definem como uma empresa de pesquisa e deploy de modelos de IA de áudio.
A qualidade da fala é impressionante. Você já deve ter visto algum vídeo em alguma rede social que foi narrado por uma voz da eleven labs. Além do TTS, eles também tem serviços que clonam voz. Mais em ElevenLabs: Free Text to Speech & AI Voice Generator | ElevenLabs
Vector Databases
Assim como temos o SQL Server, o Oracle, PostgreSQL, Elastic Search, MongoDB, etc., há mais um novo grupo de tecnologias focadas na gestão de um banco dados! São as vector databases, que, como o nome diz, são bancos de dados voltados para o armazenamento de vetores. Eu não gosto muito desse termo vetores, então, vamos simplificar: arrays. Sim, é um banco com o foco em armazenar, buscar e comparar arrays. Muito mais fácil de entender assim… Imagina você fazer isso em um banco relacional ou nosql… Vai ver que o buraco em muuuito mais embaixo…
Quando você gera um embedding de um texto, ele retorna uma arrayzão, que pode ter tamanhos variados: Pode ter 768 posições, 1024, 3072, etc… Conforme explicado acima, cada posição dessa tem um valor numérico que representa alguma característica desse texto (Se quer entender melhor, recomendo ver o artigo do Jay Alammar que deixei acima… Se ficou difícil entender, deixa um comentário aqui que eu tento adiantar um post/vídeo explicando sobre isso).
E esse valor gerado ele é comparável: Textos com significado semelhante, vão gerar embeddings com valores próximos. Existem vários algoritmos matemáticos para comparar essas arrays (lá na matemática, o nome “vetor” é mais comum). E além de comparar, você precisa ter uma forma rápida de armazenar e buscar esses valores… Aqui entra todo aquele aparato que, se você ja mexeu com banco de dados em produção (como dba, infra ou dev), sabe que precisa ter: organização de arquivos, partições, segurança, backup, alta disponibilidade, bla, bla, bla…
E aí onde nasce esses vector databases… Eles implementam vários algoritmos voltados para essa busca… Tem muitos algoritmos de comparação e de indexação de vetores… Cada um possui prós e contras… E, aqui temos um cenário bem como quando uma tecnologia nova surge: Vários “desenvolvedores “fabricantes” de Vector Dbs sugiram… E aí temos alguns como o Milvus, Qdrant, Pinecone, etc. Temos até um sqlite-vec, que é a versão do sqlite criada para todos esses algoritmos de vector db, e com apoio da Mozilla. Ou seja, uma boa chance ai que esta versão venha nativa no seu browser ou smartphone…
E o mais legal de Vector Db é que você não precisa nem de GPU para conseguir rodar… Os algoritmos são muito eficientes (❤️Matemática), e você consegue buscar pela semântica do texto usando hardware comum… Obviamente, você vai precisar de GPU um passo antes, que é para gerar os embeddings (e até isso ja já será tão eficiente que nem de GPU vamos precisar pros casos simples e médios do dia a dia).
Milvus
Eu separei um tópico só pro Milvus porque ele foi o primeiro (e único) vector database que eu tive contato até hoje (08/10/24). Subir um Milvus é relativemente simples se você está acostumado com docker. Tem o Milvus, que é o core, a engine de vector database, e o Attu, que é um interface web pra ele, muito bonita e clean.
Eu nem lembro como eu achei o Milvus, muito provavelmente foi fuçando na internet, grupos, lendo tutoriais… Mas ele é um projeto com mais de 29 mil stars no GitHub e a indexação e busca são bem rápidas. Obviamente, que eu, como alguém que tem experência e carreira em bancos de dados em produção por váriso anos, falar que “é rápido” depois de testes simples, é uma sacanagem… Mas, como envolveu textos como artigos de blog, páginas de wiki, chamados de suporte, acho que mesmo, sendo poucos gigabytes, ainda é MUITO TEXTO, e eu acho impressionante termos um software da qualidade do Milvus, completamente gratuito e que funciona muito bem para busca semântica… Certamente ele tem o seu espaço!
Eu vou ficar devendo testes, e até posts e vídeos falando só sobre o Milvus, e irei fazer isso quando tiver mais prática e experiência para agregar. Por enquanto, ainda estou criando até as ferramentas: Até pouco tempo atrás ninguém no mundo se atreveu a criar um client powershell pro Milvus. Então eu o fiz: Ps-Milvus é o nome do projeto.
Mandei isso no Discord do Milvus, os devs do Milvus curtiram tanto a ideia que publicaram ele na página oficial de integrações do Milvus:
O projeto é bem simples ainda, e implementa apenas uma funcionalidade básica de autenticação, indexação e busca… Mas já da pra usar pra indexar seu blog do wordpress, ou logs do Windows, se você quiser =). Veja exemplos aqui.
LangChain
O LangChain é uma biblioteca python muito poderosa que você pode usar para construir apps integrados com IA. A grande sacada mesmo da biblioteca é você pode conectar diversos componentes do mundo da IA de uma forma muito mais simples.
Ao criar uma app com IA, você pode ter que chamar várias e várias APIs: Pode precisar chamar a API para um LLM responder o usuário, depois gerar o embedding de um texto, depois a API para pesquiar em um vector db… E, você precisa conectar tudo isso, o que pode ser bem trabalhoso. Imagina trocar do Gpt-4 pro Gemini?
O LangChain facilita demais esse processo, trazendo diversas abstrações destas chamadas, permitindo que, por exemplo, com poucas linhas de código você crie todo o processo necessário para obter os dados do usuário, injetar na IA, processar e gerar um resultado… É como se você programasse orientado ao mundo da IA, onde todos os objetos, métodos e operações foram criados pensando nos mesmos processos envolvidos. Isso facilita criar, e substituir componentes!
Para você ter uma ideia da diferença:
- Este link é um exemplo sem usar o langchain para uma simples app que conversaria com arquivos.
- E este é um exemplo usando o langchain
Conheça mais sobre o LangChain em LangChain
LangFlow
Se o LangChain facilita muito a criação de APPs integrados com LLMs e outros recursos de IA, o LangFLow facilita ainda mais ainda usar o LangChain por um simples motivo: Ele é uma UI para o LangChain (chame como quiser: UI, low code, etc.).
Isso significa que, na maior parte do tempo você vai arrastar caixinhas que representam os mais variados componentes existentes no LangChain e conectá-los, apenas ajustando parâmetros. No final, você vai apertar um botão de play, e a mágica acontece! E se precisar, você pode customizar o código python desses componentes! É muito bacana!
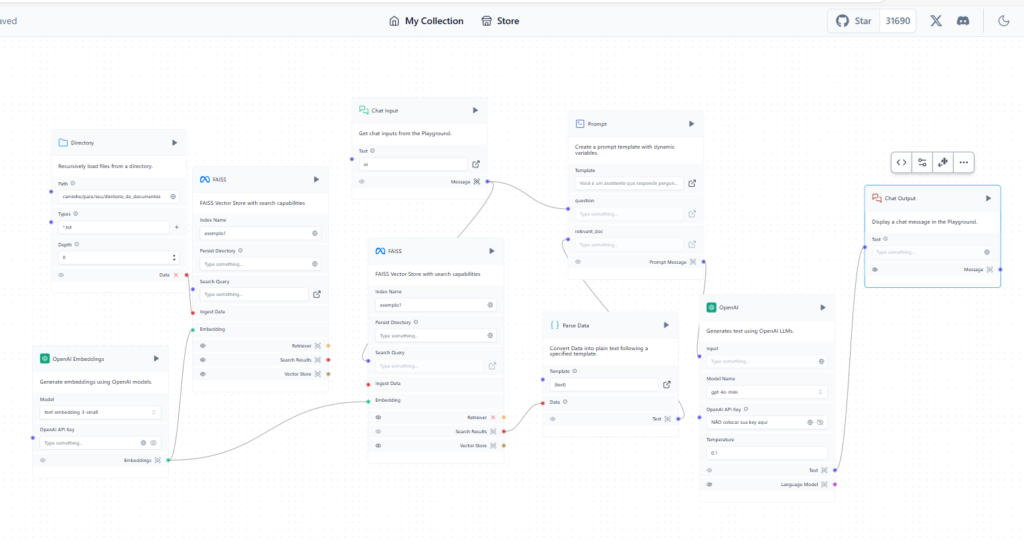
Uma outra grande vantagem do LangFlow é que, além de facilitar o desenvolvimento, ele também facilita a publicação disso em uma API ou integrar direto no seu site (se você fez um chatbot, por exemplo). Isso agiliza as coisas para quem precisa subir rapidamente algo integrado com as principais tecnologias recentes de IA.
E sabe o que é mais legal disso tudo? O LangFlow foi criado por brasileiros. Dois brasileiros lá de minas: Rodrigo Nader e Gabriel Almeida …. Fizeram um trabalham tão incrível, que foi comprada por uma empresa chamada DataStax. Mas o LangFlow segue open source você hospedar no seu proprio ambiente!
Conheça mais do projeto em Langflow – Create your AI App!
Você pode testar o langflow em diversos locais:
- Versão cloud da DataStax
- Space Oficial do Hugging Face
- Space que criei no perfil do Ia Talking (para mostrar que é possível subir facilmente um)
Apaixonado por tecnologia e veterano em bancos de dados SQL Server, este entusiasta agora se aventura no fascinante universo da Inteligência Artificial.
Atualmente é o Head de Inovação da Power Tuning, onde é o responsável por trazer novas ideias para produtos e serviços, que melhorem a produtividade do time ou a experiência do cliente! Com muita experiência em programação, hardware, sistemas operacionais, e mais, agora quer juntar tudo isso nesse novo mundo e trazer muitas ideias e conhecimento sobre Inteligência Artificial!
Neste blog, vai compartilhar sua jornada de aprendizado e uso da IA, focando em como transformar nossa maneira de resolver problemas e inovar.
Contents