
 Canal Youtube
Canal YoutubeVocê está com dúvida em algo, pesquisa no Google, não encontra fácil. Então, resolve ir ao ChatGPT e digita sua pergunta e, como num passe de mágica, pedaço por pedaço da resposta começa a surgir como se alguém lá do outro lado estivesse digitando a resposta!
Esse é um dos comportamentos do ChatGPT que o fazem parecer mais ainda com algo humano. Por debaixo dos panos, o ChatGPT tem o que chamamos de “Large Language Model”, que é um modelo de IA que “entende” e gera texto e foi treinado com muito, mas muito dados. Essa resposta dele pode ser enviada toda de uma vez, ou a medida que ele vai gerando, que é o que acontece quando você usa o ChatGPT.
Vamos ver como isso funciona na prática… O Slide abaixo expica como pode ver o Stream funcionando direto no ChatGPT:
N aba EventStream, você pode ver todas as mensagens que foram enviadas pelo endpoint /conversation do ChatGPT. O que você acabou de fazer é capturar toda essa comunicação do seu navegador com o servidor da OpenAI, e com isso podemos analisar um pouco mais como as coisas funcionam,
Essa aba EventStream te mostra tudo que foi enviado pelo servidor via Server Sent Events (SSE). Este é protocolo simples, que, com 1 mesma conexão com o servidor, ele te entrega várias mensagens (os eventos). Isso tem muitos benefícios e um dos principais é que o servidor pode te enviar mensagens a medida que for necessário, usando a mesma conexão. Para performance, é muito bom também!
Vamos ver como é o formato dessa mensagens entregue pelo ChatGPT. Podemos também usar a aba “Response”, que mostra a mesma informação, crua, como veio do servidor (ela é melhor para visualização):

Note que há vários “data: “, seguido de um JSON. E é exatamente esse formato documentado do protocolo do SSE. No caso da OpenAI, cada JSON contém o pedaço da mensagem gerada pelo LLM. Se você rolar um pouco, vai ver que em um dado momento vai aparecer algo como isso:

Note a resposta da minha imagem e esse conteúdo. É exatamente o pedaço da minha informação chegando. Esse padrão vai se repetir, com vários tipos de mensagens que a interface do ChatGPT precisa. No final, ele encerra com um [DONE], indicando que enviou tudo que queria:

Na API da OpenAI, o processo é um pouquinho diferente, mas a ideia é a mesma. Recentemente, eu atualizei o módulo powershell chamado PowershAI, adicionando o suporte ao Stream, que usa o mesmo princípio do ChatGPT que você viu acima.
Para usar o stream, você precisa passar o parâmetro stream = true e processar a resposta até que receba um “data: [DONE]” da OpenAI. Aqui está um pequeno exemplo de como fiz isso usando algumas funções do próprio PowershAI:
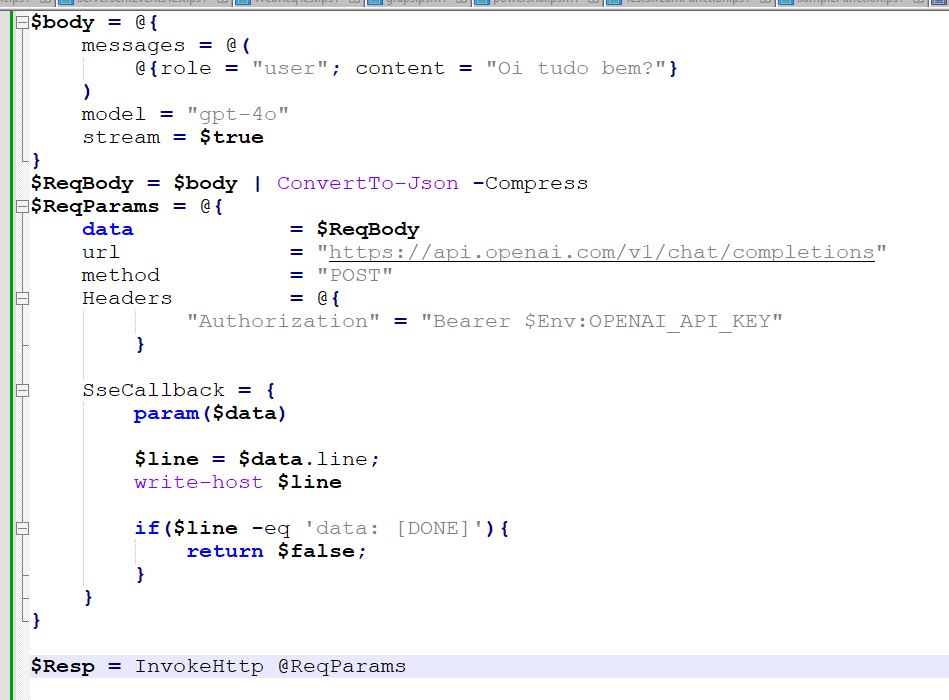
Você pode conferir a função InvokeHttp diretamente na fonte, mas, em resumo, ela encapsula a chamada para a WebRequest do .net (que é depreciado, mas ainda serve para muitos testes). O script acima produziu o resultado abaixo:
O resultado completo:
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}
ta":{"content":"Oi"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":"!"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"del
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" bem"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":","},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" e"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" você"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":"?"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" Como"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" posso"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" ajudar"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":" hoje"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{"content":"?"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-9bTSkS3tR5h3HVvzmR8OROVQW86PC","object":"chat.completion.chunk","created":1718718418,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_f4e629d0a5","choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
data: [DONE]Code language: PHP (php)Para você comparar, esse é o resultado sem o Stream:
{
"id": "chatcmpl-9bU2cH8NrDzMpvBHKIXRDm53DJoYp",
"object": "chat.completion",
"created": 1718720642,
"model": "gpt-4o-2024-05-13",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Oi! Tudo bem, e você? Posso ajudar com alguma coisa?"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 11,
"completion_tokens": 15,
"total_tokens": 26
},
"system_fingerprint": "fp_9cb5d38cf7"
}Code language: JSON / JSON with Comments (json)Repare que no campo choices.delta.content, a mensagem vem sendo entregue quebrada. O segredo do Stream é justamente esse: Ele vai te enviando a medida que vai gerando a resposta, e por isso a mensagem vem quebrada nesse formato.
Uma vez que você tem esse resultado, você pode exibir diretamente, bastando apenas converter o JSON, pegar o conteúdo e ir escrenvendo para onde quiser: tela, browser, arquivo , etc. (faz mais sentido na tela, interativo com o usuário).
Mas isso não é tudo. Para conseguir criar todo o fluxo de conversa, mantendo o histórico, interpretando as functions calls, você precisa ser capaz de devolver as próprias respostas pra API, só que tudo junto. E, principalmente quando há function calling no meio, isso vai deixando o código um pouco mais complexo.
Apesar da observação confirmar, eu só fiquei tranquilo em implementar isso depois que esse comportamento é o oficial e documentando pela OpenAI: API Reference – OpenAI API

Como eu fiz no PowershAI
O PowershAI é um módulo powershell que eu criei para interagir com a OpenAI (e futuramente outros serviços) diretamente do seu prompt. O principal motivo de ter criado ele foi aprender a usar a API da OpenAI!
Recentemente eu implementei o Stream nele, e isso que originou esse post, pois aprendi muito sobre como ele funciona para usar na prática (incluindo o uso dele com o Tool Calling).
Ao processar o stream, ele junta toda a resposta quebrada em 1 só. Então, sempre que eu leio o Stream da API, além de escrevê-lo diretamente na tela (usando o comando Write-Host -NoNewLine), eu mantenho um objeto separado com toda a resposta junta. Quando o stream termina, a resposta sai completa na tela (dando a sensação de resposta digitada que você já conhece) e também tenho toda a resposta pronta para ser usada e enviada de volta ao modelo, se precisar.
Este é o trecho que faz isso. Este código é executado para cada linha que a API da OpenAI me retorna quando o stream é ativado. Na variável $line, está o conteúdo dessa linha.

Quando ele começa com data: { significa que é uma linha que contém o JSON com a mensagem, então eu extraio algumas informações do JSON e valido, por exemplo, se tem Tool Calls. Eu fiz algumas testes e, por observação, eu notei que quando há tools calls, ele geralmente não envia nenhuma outra mensagem junto (mas não assumo que é sempre que isso acontece). Aqui, eu extraio todas as calls e guardo num objeto que irei usar posteriormente para invocar as tools e devolver a resposta pro modelo (quando o modelo invoca uma tool, se eu quero que ele continue a resposta, preciso enviar de volta a mensagem em que ele invocou seguido da mensagem com as resposta pra cada invocação).
E repare que na variável $StreamData.fullContent eu vou concatenando a resposta. No final, toda essa resposta junta estará lá para ser usada como eu precisar.
Logo abaixo, ainda tem mais um pedaço em que faço mais algumas tratativas:

Ali no início, onde tem um & $StreamCallback $Answer, é onde eu invoco o script para fazer o que quiser com o resultado. A função que você está vendo não é uma função que utilizo em vários outros comandos. Ela encapsula toda a lógica complexa que precisa lidar com a API da OpenAI. Este callback é um script que passo, onde eu ainda mantenho o controle sobre cada reposta enviada pelo server, a medida que chega.
E logo abaixo na imagem, repare que no if se a resposta foi um Stream, então, eu monto uma estrutura que será retornada e que possui praticamente a mesma estrutura da resposta sem o Stream. Isso me permite reusar quase que o mesmo código tanto pra Stream quanto pra sem Stream.
Tem muito mais detalhes que daria pra falar, mas o post já ficou muito maior do que eu queria. Então, vamos deixar para a próxima. Se você quiser mais detalhes, pode conferir o código diretamente no GitHub, ou, se ficou com dúvidas, fica a vontade para perguntar nos comentários aqui, ou em qualquer canal de comunicação do Ia Talking!
O vídeo abaixo é um exemplo comparando o funcionamento com e sem stream:
Apaixonado por tecnologia e veterano em bancos de dados SQL Server, este entusiasta agora se aventura no fascinante universo da Inteligência Artificial.
Atualmente é o Head de Inovação da Power Tuning, onde é o responsável por trazer novas ideias para produtos e serviços, que melhorem a produtividade do time ou a experiência do cliente! Com muita experiência em programação, hardware, sistemas operacionais, e mais, agora quer juntar tudo isso nesse novo mundo e trazer muitas ideias e conhecimento sobre Inteligência Artificial!
Neste blog, vai compartilhar sua jornada de aprendizado e uso da IA, focando em como transformar nossa maneira de resolver problemas e inovar.




